
스프링 카프카 Batch Consumer - 의도치 않은 리스너 호출
개요
- 스프링 카프카 Batch Consumer 를 사용하는데, 의도하지 않은 @KafkaListener 호출이 발생했다.
- 스프링 카프카 소스를 까본 내용을 정리해보았다.
TL;DR
- spring kafka batch consumer 를 사용할때 누적 메시지 사이즈나 레코드 개수를 기준으로 가져오는 것이 아닌, 일정한 시간간격을 가지고 읽어들이고 싶은 경우에
- @KafkaListener 메서드의 호출은, 카프카 클러스터를 구성하는 브로커 개수만큼(최대) 발생할 수 있다.
- 백그라운드에서 무한루프를 돌면서 polling 을 하고 있는데, 노드별로 비동기로 fetch 요청을 보내기 때문이다.
- spring kafka 2.3 버전이후부터 제공되는 ContainerProperties 의
idleBetweenPolls값으로 해결할 수 있다. - KafkaMessageListenerContainer 내부 콜 시퀀스 다이어그램
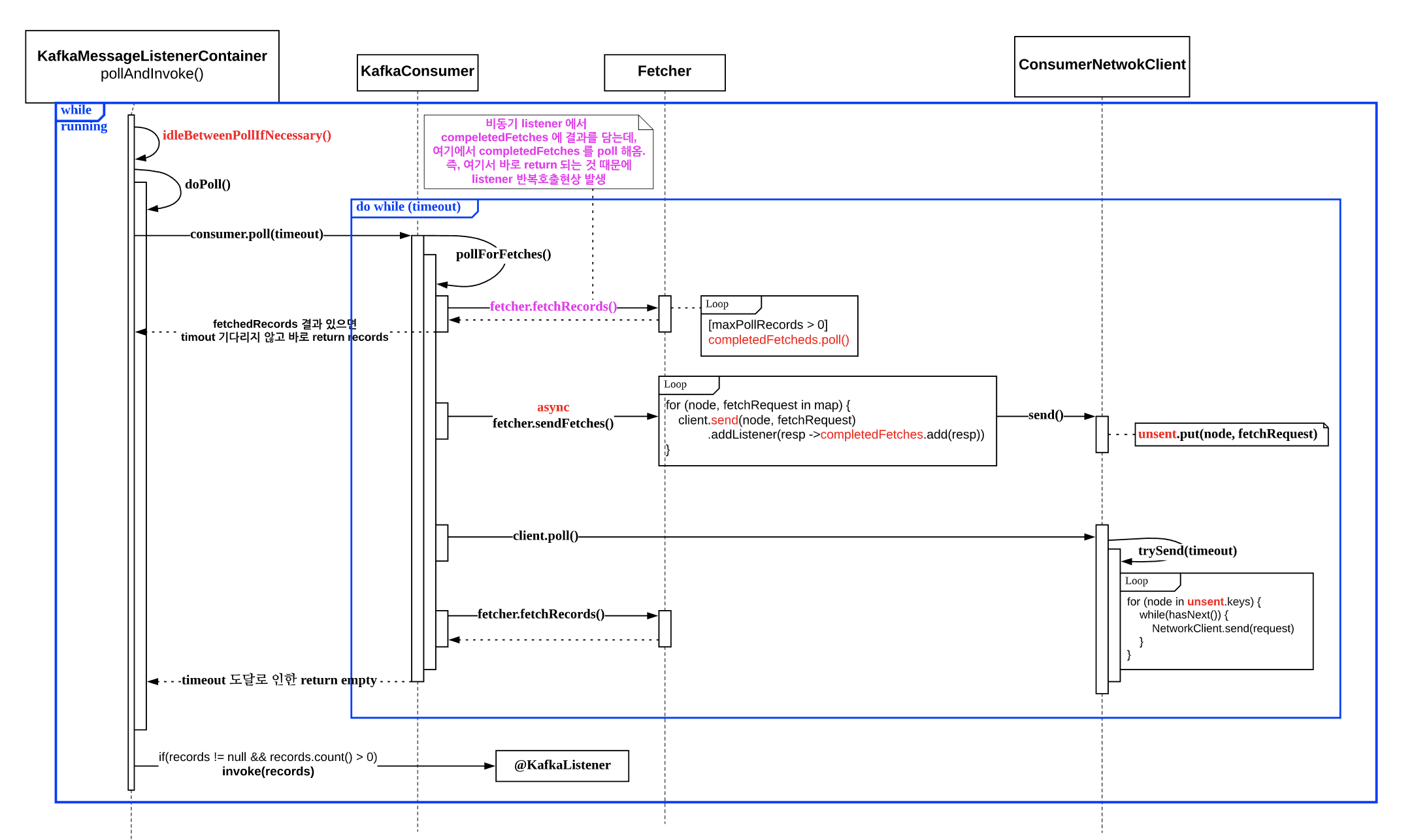
아래부터는 파악하는 과정을 적어 보았다. (길어요 ㅠㅠ)
사용버전
- java 11
- spring boot 2.2.6.RELEASE
- spring kafka 2.3.7.RELEASE
- apache kafka client 2.3.1
배경
hive 로 적재하는 consumer group 하나가 있고, 같은 topic 에 붙어서 통계수치를 집계하는 다른 consumer group 을 추가해야할 일이 생겼다.
10초 간격으로 메시지들을 가져와서 group_no (각 메시지들을 그룹핑 할 수 있는 기준 값) 를 기준으로 집계하여 통계DB 를 업데이트하는 작업이었다.
하고자 했던 것
- 10초에 1회
@KafkaListener메서드가 호출되도록 설정한다. - 받아온 메시지들을 각각 group_no 를 기준으로 grouping 한다.
- 같은 group_no 로 들어온 메시지들이 몇개인지 DB 에 업데이트를 한다.
비교적 간단한 작업이었다. 근데 kafka 는 처음이라 좀 오래 걸렸다. (아직 쪼렙이라 다 처음이다 ^__^)
하고자 했던 것을 하기위해
consumer 관련 프로퍼티 설정
spring.kafka.consumer.max-poll-records=6000
spring.kafka.consumer.fetch-min-size=1MB
spring.kafka.consumer.fetch-max-wait=10s
| key | default | description |
|---|---|---|
| max.poll.records | 500개 | 10초에 한번 가져오도록 구성할 것이므로 충분히 큰 값으로 지정 –> 6000개로 변경 |
| fetch.min.bytes | 1byte | consume 할 메시지가 최소 1byte 라도 있으면 fetch 하는 것이 디폴트 –> 1MB 채워지기 전까지는 fetch 하지 않도록 변경 |
| fetch.max.wait.ms | 500ms | fetch.min.bytes 가 채워지지 않았다면 최대 500ms 동안 block 하는 것이 디폴트 –> 10초로 변경 |
1MB 가 채워지거나, 6000개 레코드가 채워지지 않으면 10초 동안 기다려라
code configuration
- AbstractKafkaListenerContainerFactory 의 batchListener 설정을 true 로
- ContainerProperties.AckMode.BATCH 사용
- 리스너에서 MyLogType 에 바로 매핑시킬 수 있도록 MyLogType 은 org.apache.kafka.common.serialization.Deserializer 를 구현
@Bean
public ConcurrentKafkaListenerContainerFactory<String, MyLogType> kafkaListenerContainerFactory(
ConsumerFactory<String, MyLogType> consumerFactory
) {
var factory = new ConcurrentKafkaListenerContainerFactory<String, MyLogType>();
factory.setConsumerFactory(consumerFactory); // deserializer 를 구현한 consumer factory
factory.setBatchListener(true);
factory.setBatchErrorHandler(new SeekToCurrentBatchErrorHandler());
var containerProperties = factory.getContainerProperties();
containerProperties.setAckMode(ContainerProperties.AckMode.BATCH);
return factory;
}
Listener
여러개 레코드들을 ConsumerRecords 에 담아서 돌려주면, value 만 뽑아내서 적당히 필터링하고, group_no 별로 카운트한뒤에, 집계된 수치만큼 DB 에 업데이트 하면 됨!
@KafkaListener(topics = "${spring.kafka.template.default-topic}")
public Integer onMessage(ConsumerRecords<String, MyLogType> consumerRecords) {
StreamSupport.stream(consumerRecords.spliterator(), false)
.map(ConsumerRecord::value)
.filter(Objects::nonNull)
.filter(MyLogType::isCountable)
.collect(groupingBy(MyLogType::getGroupNo, counting()))
.forEach(repository::updateCount);
log.info("{}_consumed:{}", rand.nextInt(10), consumerRecords.count());
return consumerRecords.count();
}
10초에 한번씩 listener 가 호출되어 배치처럼 돌겠지?
잘되려나? - 내로잘
일단 deserialize exception 발생하는건 잠시 무시하고, kafka-producer-perf-test 를 이용해서 10초에 한번씩 호출되는지 확인해본다.
kafka-producer-perf-test.sh --topic log-topic-local --num-records 15000 --record-size 100 --throughput 500 --producer-props bootstrap.servers=localhost:9092
–> 1 record 에 100byte 짜리 메시지를 1초에 500개씩 총 15000개 보내라
- kafka-producer-perf-test 는 30초동안 실행됨
- 1초에 500개씩 produce, 1초당 생산되는 데이터는 500 * 100 = 50000byte = 500KB
- 10초 동안 보내도
- 500KB * 10초 = 5000KB 로 fetch-min-size 인 1MB 가 안되고,
- 500개/s * 10초 = 5000개 로 max-poll-records 인 6000 이 안됨
- 즉, 10초에 한번씩 5000개 언저리의 메시지를 fetch 해올 것으로 예상
- 리스너 메서드는 10초에 한번씩 1회 호출되며, 5000개 언저리의 카운트를 출력할 것으로 예상
결과

첫 호출건과 마지막 호출건은 5000개 가 다 채워지지 않을 수 있다. 약간 밀리기는 하지만 어쩔수 없고, 의도했던 10초에 한번씩 Listener 메서드가 호출되어 배치처럼 동작하는 것을 확인할 수 있다.
개발용 카프카 붙여서해보자
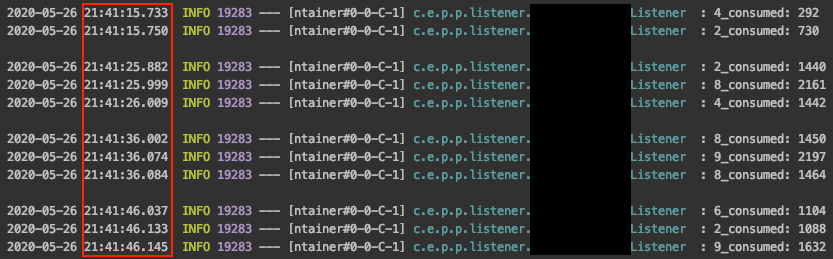
얼레??? 10초 간격으로 호출되기는 했지만 Listener 메서드가 3번씩 호출된다.
뭐지? 추측
잘됐던 테스트는 로컬에 있는 카프카를 사용했다. 클러스터를 구성하지 않은 1대의 브로커만 있는 카프카였고, 개발용 카프카는 3대의 노드로 구성된 카프카 클러스터이다. 노드 개수와 리스너 호출수 사이에 상관관계가 있는 것 같다!
그냥 넘어갈까?
가정이 맞다면 7대로 구성된 운영환경 카프카 클러스터에서는 10초마다 7번씩 리스너 호출이 발생할 수 있고,
consumer 는 1대가 아니라 여러대를 둘 것이기 때문에, 실제로 DB 업데이트 쿼리가 호출되는 횟수는 10초마다 node수 * consumer수 만큼 호출될것이다.
현재는 producer 에서 던지는 메시지가 round-robin 으로 브로커에 전달된다. producer 에서 key 를 줘서 던지면 같은 key 를 가지는 메시지는 같은 파티션으로 가기 때문에, 같은 group_no 가 여러개의 파티션으로 분산되는 지금보다 DB관점에서는 부하가 덜해지겠지만 완전한 해결방법은 아니다.
또한, group_no 마다 들어오는 메시지수가 일정하지 않고, 어떤 것은 엄청 많고 어떤것은 거의 없고 그렇다. 그래서 특정 partition 으로 메시지가 쏠릴수 있다.
문제가 된다.
왜이러지? 확인
먼저 @KafkaListener 를 호출하는 곳을 찾아야한다.
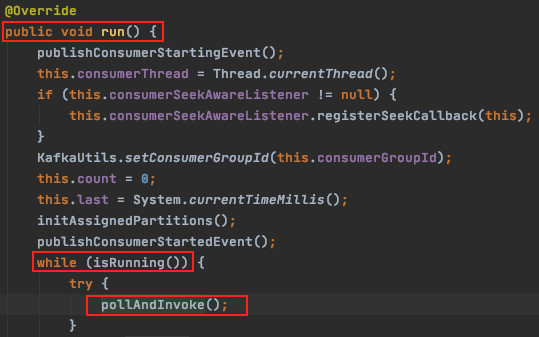
1. KafkaMessageListenerContainer.pollAndInvoke()
KafkaMessageListenerContainer 로 가면 run() 메서드가 있는데, 여기에서 무한루프 while 문이 실행되어 설정값에 설정한 대로 주기적으로 poll 해오는 곳이다. while 문 내에서 실행되는 pollAndInvoke() 안에서 중요한 모든 일들이 일어난다고 봐도 된다. (아래)
(아래) pollAndInvoke() 메서드 내부를 들여다 보면, doPoll() 메서드로 records 를 가져와서 invokeListener(records) 를 통해서 넘겨주면 @KafkaListener 가 호출된다. 이부분이 무한루프 안에서 연쇄적으로 호출되어서 리스너 호출이 브로커 개수만큼 일어나는 것 같다.
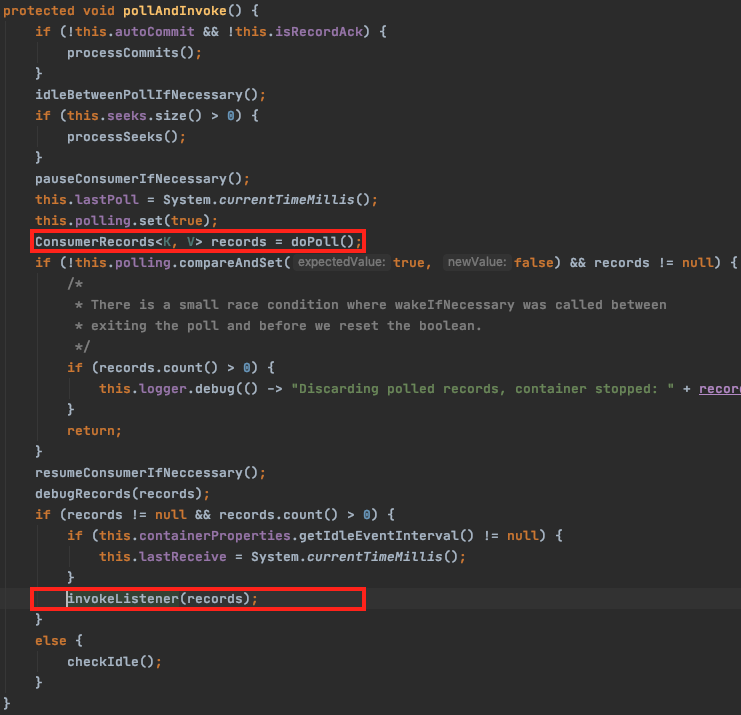
invokeListener() 는 구동시점에 @KafkaListener 로 등록된 메서드를 호출하는 것 외에 딱히 하는건 없으니, doPoll() 안에서 무슨일이 벌어지는지 확인할 필요가 있다.
2. KafkaMessageListenerContainer.doPoll()
subBatchPerPartition 설정은 디폴트가 false 이므로 else 로 가게 되어, KafkaConsumer 의 poll() 을 호출한다. (poll timeout 은 별도 설정하지 않으면 ConsumerProperties.DEFAULT_POLL_TIMEOUT 인 5000ms 가 적용된다)
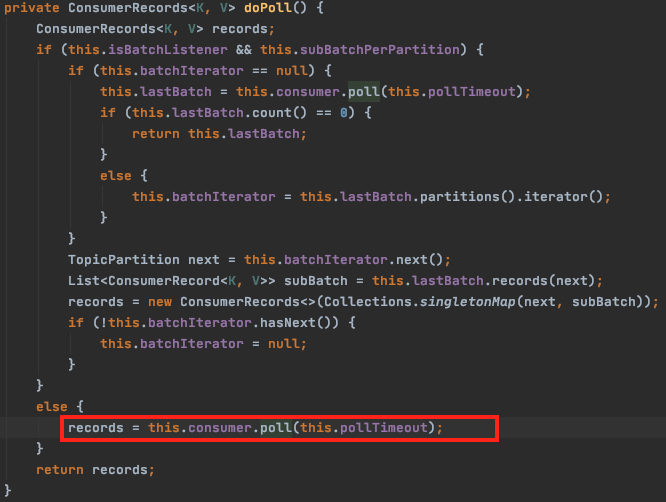
3. KafkaConsumer.poll()
이 안에서는 poll timeout 으로 지정한 시간만큼 루프를 돌면서 pollForFetches(timer) 를 호출한다.
(등록한 인터셉터로 records 를 넘기는 것도 볼 수 있다)
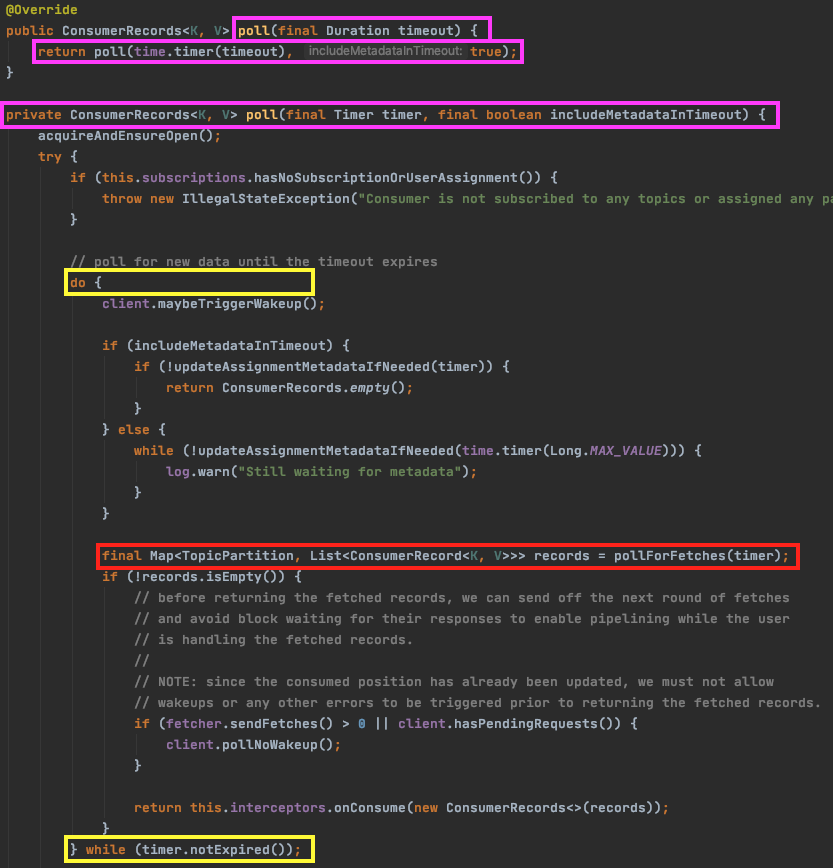
4. KafkaConsumer.pollForFetches(timer) - 핵심
리스너가 왜 노드 개수만큼 호출되는지에 대한 원인을 찾아볼 수 있는 함수이다. 이 메서드가 하는 일은 동기적으로 생각하면 간단하다. fetch 요청을 보내고, fetch 된 데이터가 있으면 반환하는 게 전부다.
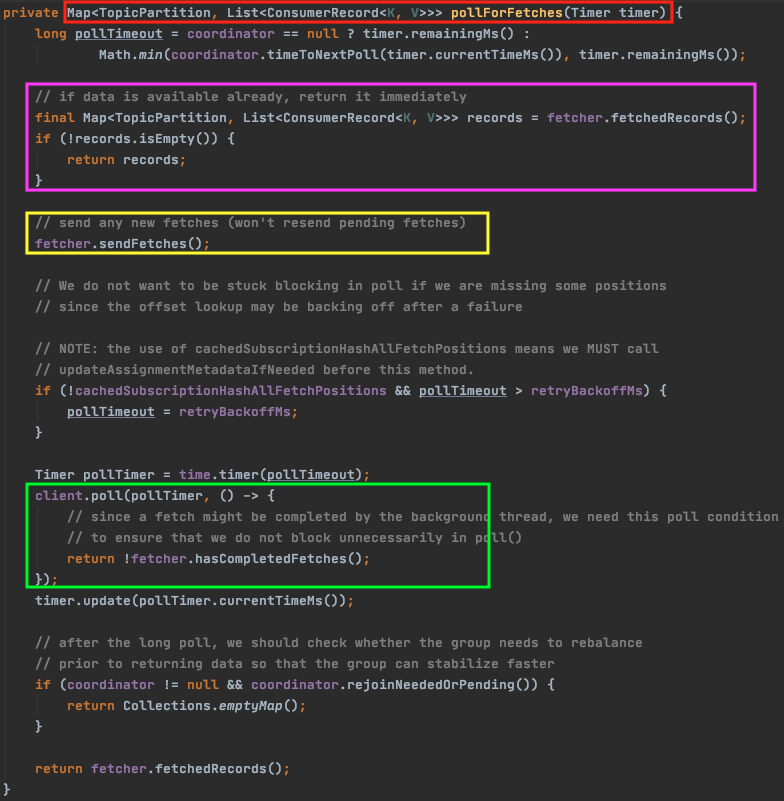
그런데 비동기로 구성되어 있어서 좀 헷갈린다. 비동기적으로 동작하기 위해서 내부적으로 2개의 큐를 이용한다. ConcurrentLinkedQueue 타입의 completedFetches 와 ConcurrentMap 타입의 unsent 이다.
completedFetches 는 fetch 가 완료된 데이터를 가지는 큐이고, unsent 는 fetch 요청을 담는 큐이다. 큐를 사용해서 비동기로 fetch 요청을 보내고, 받아온 데이터를 반환하는 방식은 아래와 같다.
| 호출부 | 설명 |
|---|---|
| fetcher.fetchedRecords() | completedFetches 큐에 레코드가 있으면 반환한다. 어디선가 이 큐에 데이터를 계속 채우고, 여기서는 데이터가 있으면 설정한 개수만큼 가져와서 리턴하기만 한다. |
| fetcher.sendFetches() | fetch 요청을 노드별로 unsent 큐에 담는다. 이 메서드에는 RequestFuture 타입을 반환하는데, 이 Future 의 onSuccess 콜백 메서드에서 fetch 가 완료된 레코드들을 completedFetches 큐에 넣는다. |
| client.poll() | ConsumerNetworkClient.poll() 메서드 내부에서, unsent 큐에 담긴 fetch 요청을 실제로 네트워크를 태워서 보낸다. |
(코드가 순차적으로 실행이 되기는 하지만, 무한루프 내에서 계속 호출되기 때문에 어떤 큐에 언제 데이터가 들어가고, 큐에 데이터가 있을 경우 어떤 동작을 하는지 큐를 중심으로 코드의 흐름을 파악해야한다.)
중요한 부분
unsent 큐에 fetch 요청을 담을때에 노드별로 담고, 실제로 fetch 요청을 보낼때에도 노드별로 요청을 보낸다는 것이다.
노드가 3개라고 치면, 3개의 요청이 unsent 큐에 담기고, 3개의 요청을 보내고, completedFetches 큐에 3개 노드에서 fetch 해 온 레코드들이 채워질때마다 return 을 하게되어 총 3번의 return 을 하게 된다. return 하면 doPoll() 을 호출했던 곳으로 쭉쭉쭉 리턴하게 되는데, 다음에는 invokeListener(records) 메서드 호출이 기다리고 있고, 여기서 @KafkaListener 메서드 호출이 총 3번 발생한 것이다.
해결방법
spring kafka 2.3 이상 버전이라면 ContainerProperties 에 idleBetweenPolls 값을 주어서 해결할 수 있다.
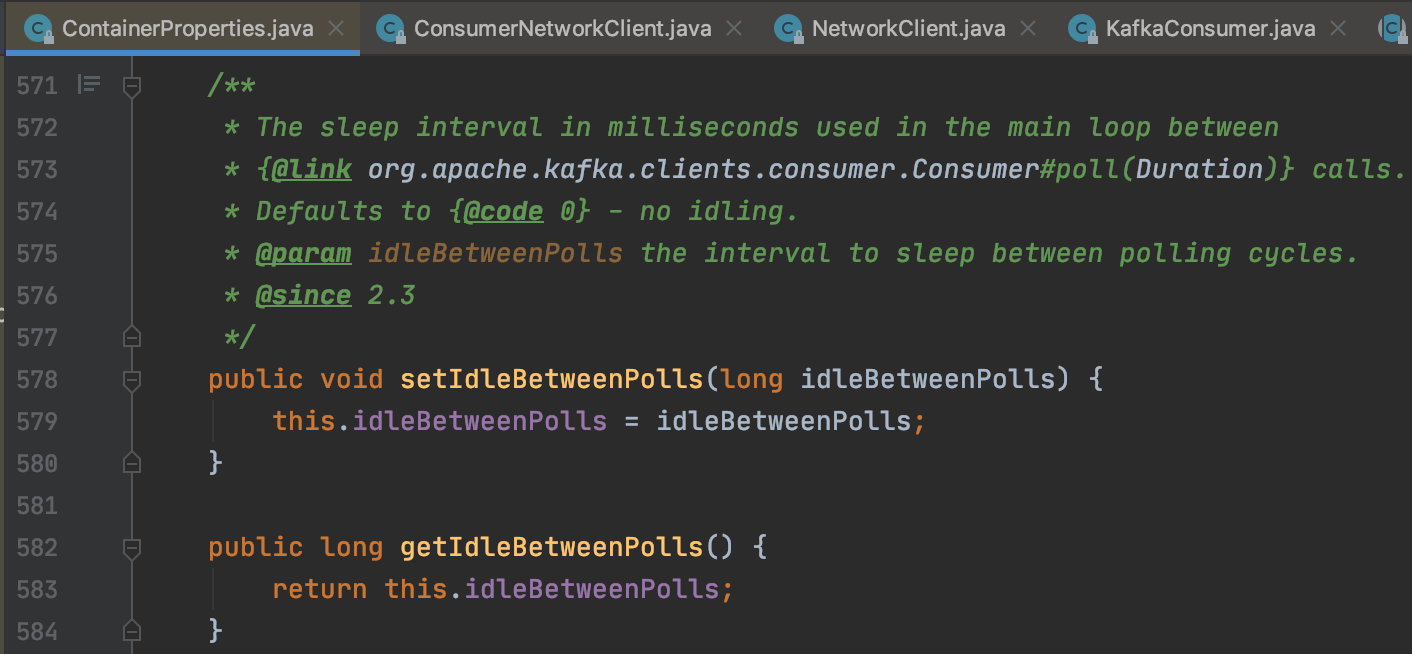
run() 메서드 무한루프 내에서 실행되는 pollAndInvoke() 메서드는 doPoll() 을 호출하기 전에 idleBetweenPollIfNecessary() 라는 함수를 먼저 호출한다.
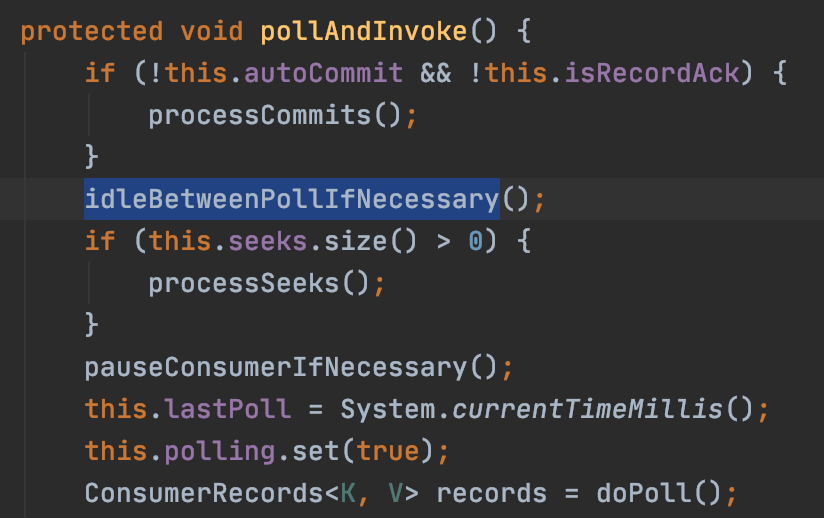
idleBetweenPollIfNecessary() 는 이렇게 생겼다.
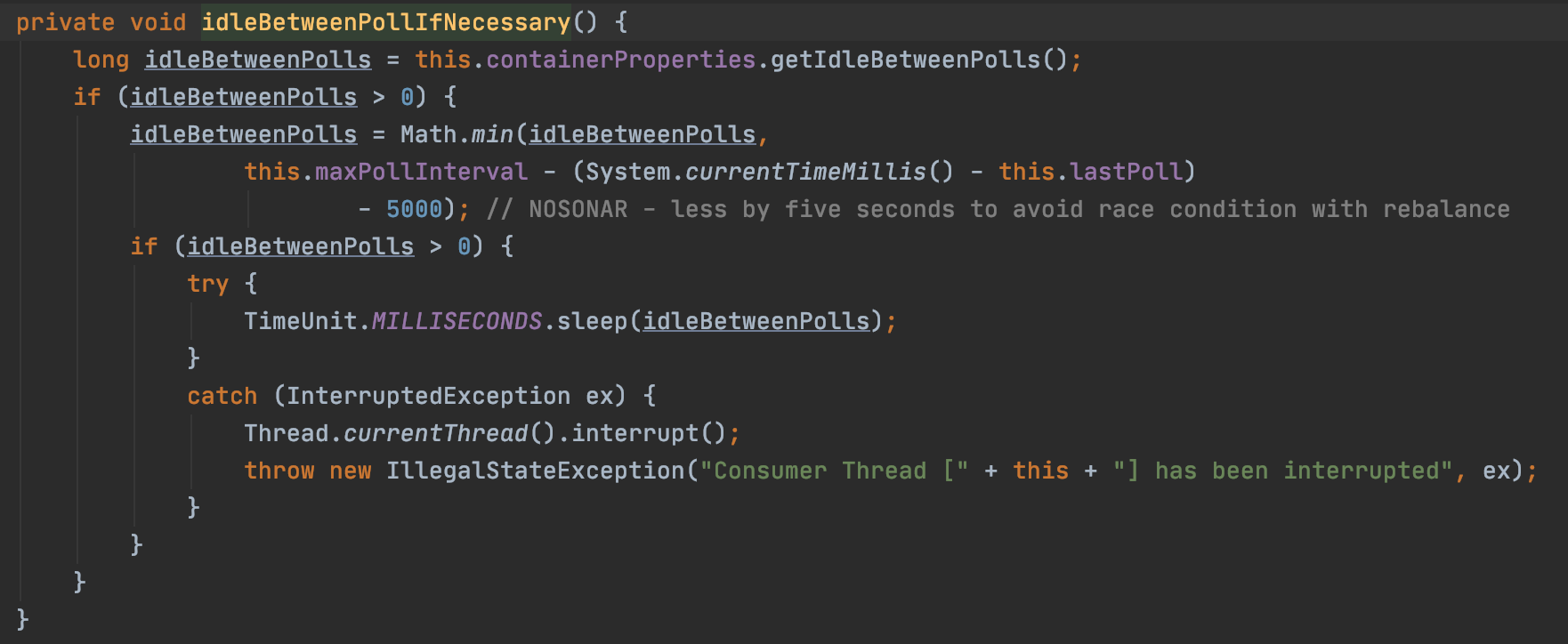
idleBetweenPolls 값이 0보다 크면 설정한 값만큼 스레드를 sleep 하여 루프의 진행을 멈추도록 한다. 이 메서드는 doPoll() 메서드 이전에 호출이 되기 때문에 completedFetches 큐에 데이터가 채워질때마다 리턴하는 것을 block 함으로써, fetch 시간동안 기다려서 노드별로 fetch 해온 데이터를 completedFetches 큐에 모두 쌓은다음, idleBetweenPolls 시간이 종료되면 한번에 return 하게 된다.
주의할 점은
idleBetweenPolls = Math.min(
idleBetweenPolls,
this.maxPollInterval - (System.currentTimeMillis() - this.lastPoll) - 5000
)
코드에 의해 항상 내가 설정한 idleBetweenPolls 값대로 먹히는게 아니다. max.poll.interval 은 기본값이 30000ms 인데 25초보다 작은 경우에만 의도한대로 동작하고, 25초보다 크게 설정할 경우 max.poll.interval 도 수정해주어야 한다.
Call Sequence Diagram
지금까지 설명한 과정을 시퀀스 다이어그램으로 표현하면 아래와 같다.
지금까지 과정을 다시한번 돌아볼겸 시퀀스 다이어그램 기준으로 다시 설명해보면
- fetch 요청을 보낼때 (비동기)
- 직접 발송하지 않고 unsent queue 에 담기만 한다.
- ConcurrentMap<Node, ConcurrentLinkedQueue
> unsent
- ConcurrentMap<Node, ConcurrentLinkedQueue
- 응답을 받으면 callback 리스너에서 completedFetches 에 응답결과를 추가
- ConcurrentLinkedQueue
completedFetches
- ConcurrentLinkedQueue
- 직접 발송하지 않고 unsent queue 에 담기만 한다.
- 실제 fetch 요청 전송
- ConsumerNetworkClient.poll() 내부에서 trySend() 호출시 node 별로 요청을 전송
- 그래서 원인은
- pollAndInvoke() 를 호출하는 while 문은 앱 구동중에 무한루프를 돌고 있음
- 이때 fetch 요청은 설정값대로 1MB 나 6000 레코드가 채워지기 전까지 10초를 기다림
- 그 와중에도 pollAndInvoke() 호출이 있는 루프는 계속 돌고있음
- fetch-max-wait 이 지나서 fetch 가 끝나면, 콜백리스너에서 completedFetches 에 각 노드별에서 돌려 받은 레코드를 파티션별로 add
- 노드가 7개라면, 7개의 요청을 보냈을 것이고, 최대 7번 콜백리스너가 호출될 수 있음
- 이 와중에도 루프는 계속 돌고 있는데, 돌다가 fetcher.fetchRecords() 결과로 records 가 있는 것을 보고 바로 반환을 하고,
- (fetchRecords() 에서 compeletedFetches 큐에서 꺼내옴)
- pollAndInvoke() 로 돌아와서 다음 코드를 진행하는데, records 가 있으므로 invoke() 메서드를 호출하게 되고, 결국 노드 갯수만큼 호출함