
Spark 시작하기 1.3 - AWS EMR 로 인스턴스 5대 클러스터링 해서 Spark 돌려보기
소스 받기
$ git pull https://github.com/yaboong/spark-study-project.git
개요
지금까지 spark 를 local machine 에서 standalone 으로만 돌렸다. 단순 스크립트로 54분이 걸리는 작업을 spark 로는 90초 밖에 걸리지 않는 것을 확인했다. 그러면 AWS EMR(Elastic Map Reduce) 의 도움을 받아 클러스터링 해서 돌리면 얼마나 더 빨라질까?
AWS EMR cluster 생성
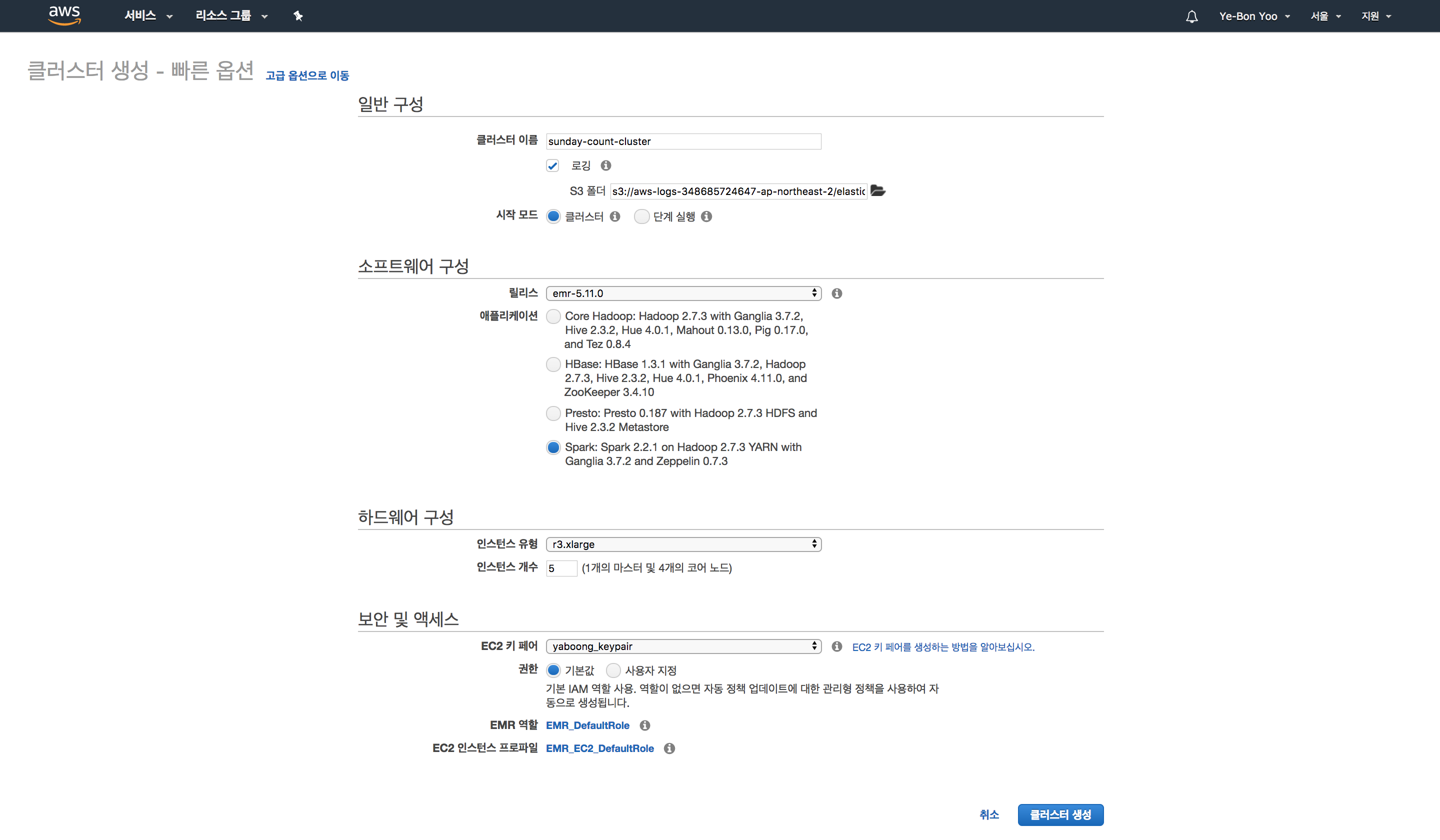
위와 같이 클러스터를 생성한다. r3.xlarge 로 5대를 생성했기 때문에.. 빨리 돌려보고 종료시켜야 한다. 켜져 있는 시간만큼 비용이 청구되기 때문에 요금 폭탄 맞을 수도 있다. EMR cluster list 에서 sunday-count-cluster 를 클릭해서 들어가면 아래와 같은 화면을 볼 수 있다.
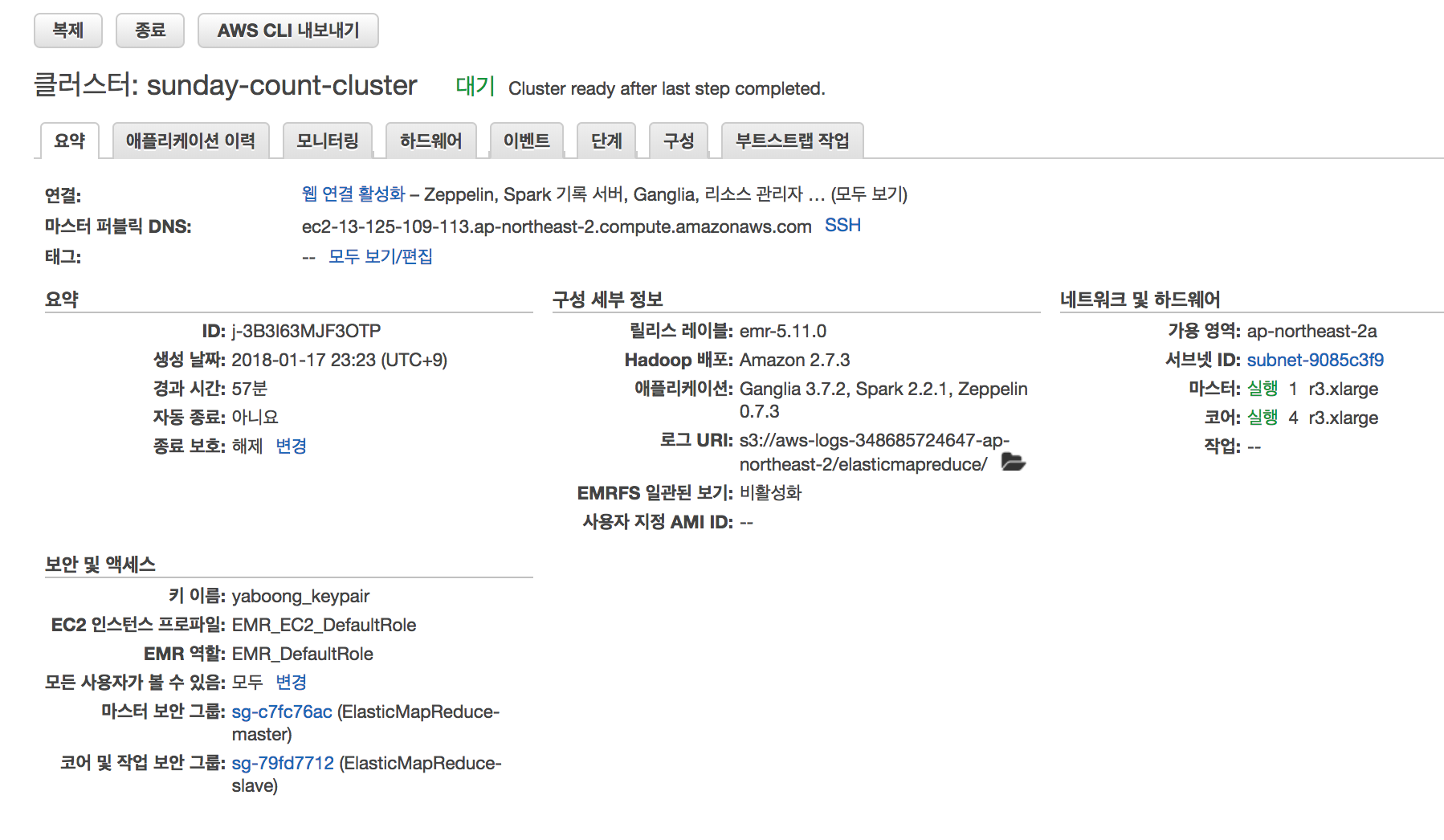
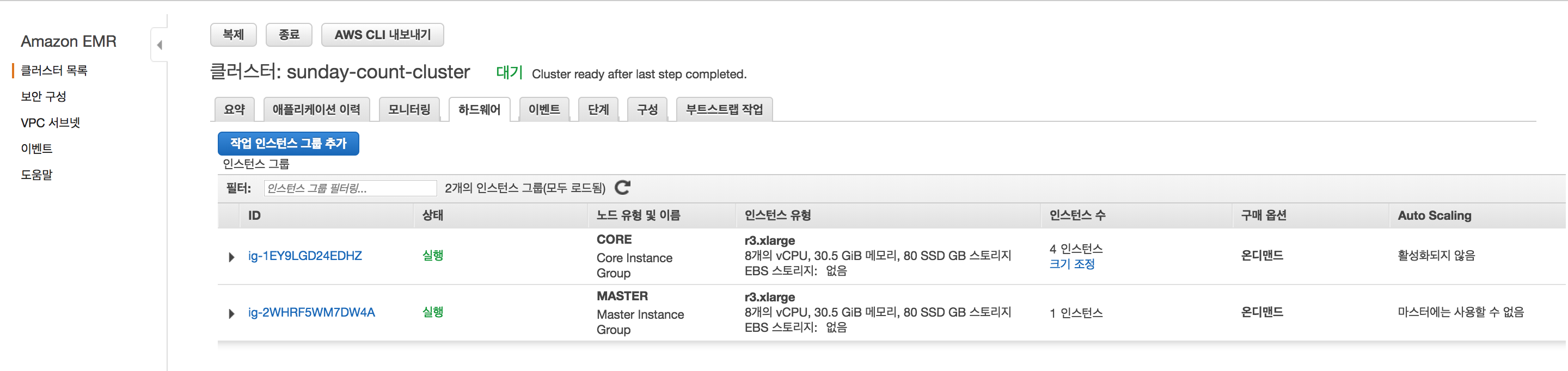
말 그대로 요약이고, 마스터 노드에 스파크 애플리케이션을 배포할 것이기 때문에 마스터 노드에 대한 정보를 보자. 하드웨어 탭을 누르면 아래와 같이 마스터 1대, 슬레이브 노드 4대의 인스턴스로 구성 된 것을 볼 수 있다.
Security Group 설정
마스터 인스턴스에 ssh 로 접속해서 코드를 받을 것이므로, 내가 사용하는 IP 로 ssh 액세스를 할 수 있도록 보안그룹을 세팅해줘야 한다.
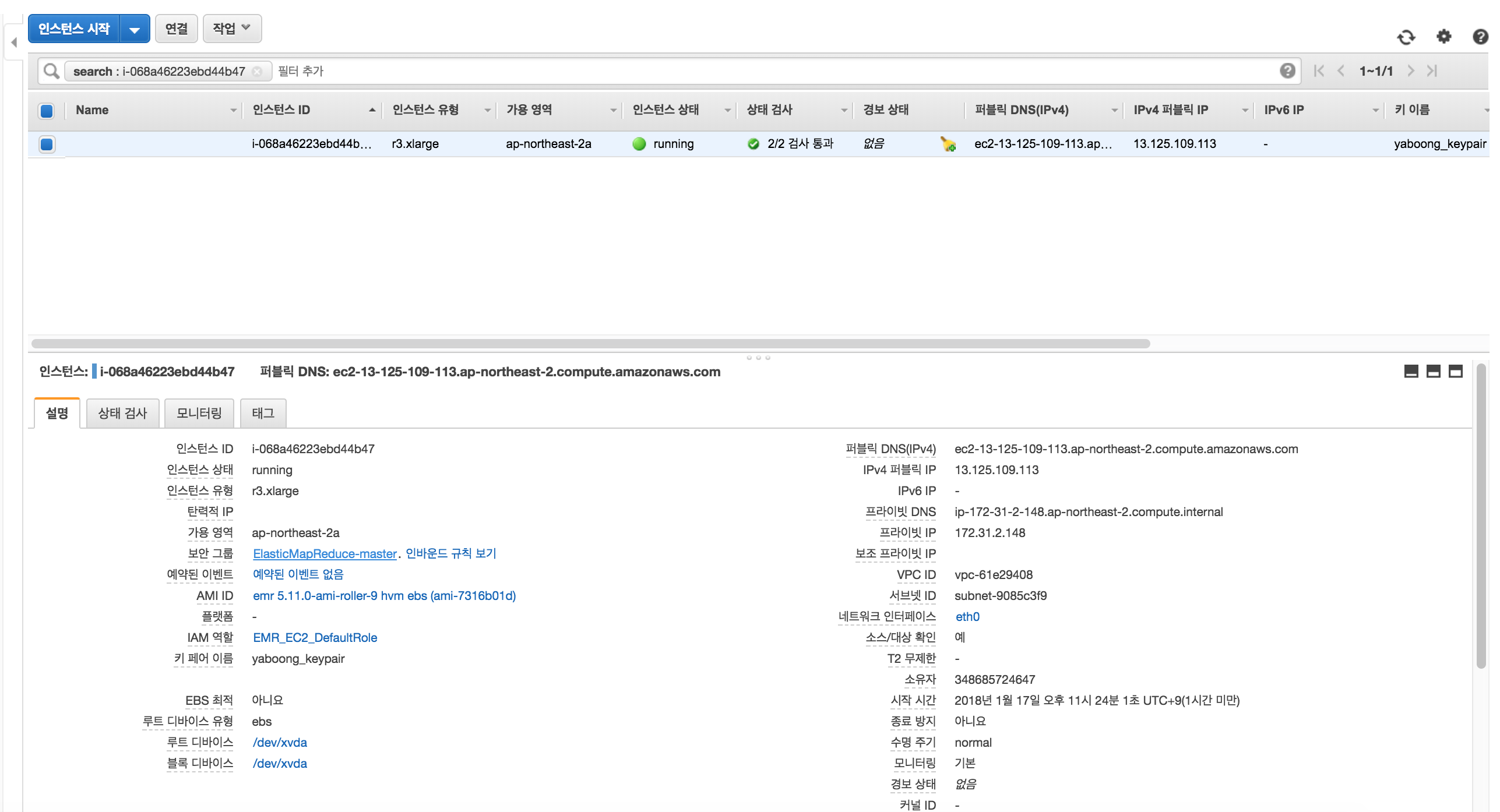
마스터 인스턴스로 가면 위와 같은 화면이 나오는데, 보안그룹에 ElasticMapReduce-master 를 클릭해서 아래와 같이 보안그룹을 설정 해 줘야 한다.
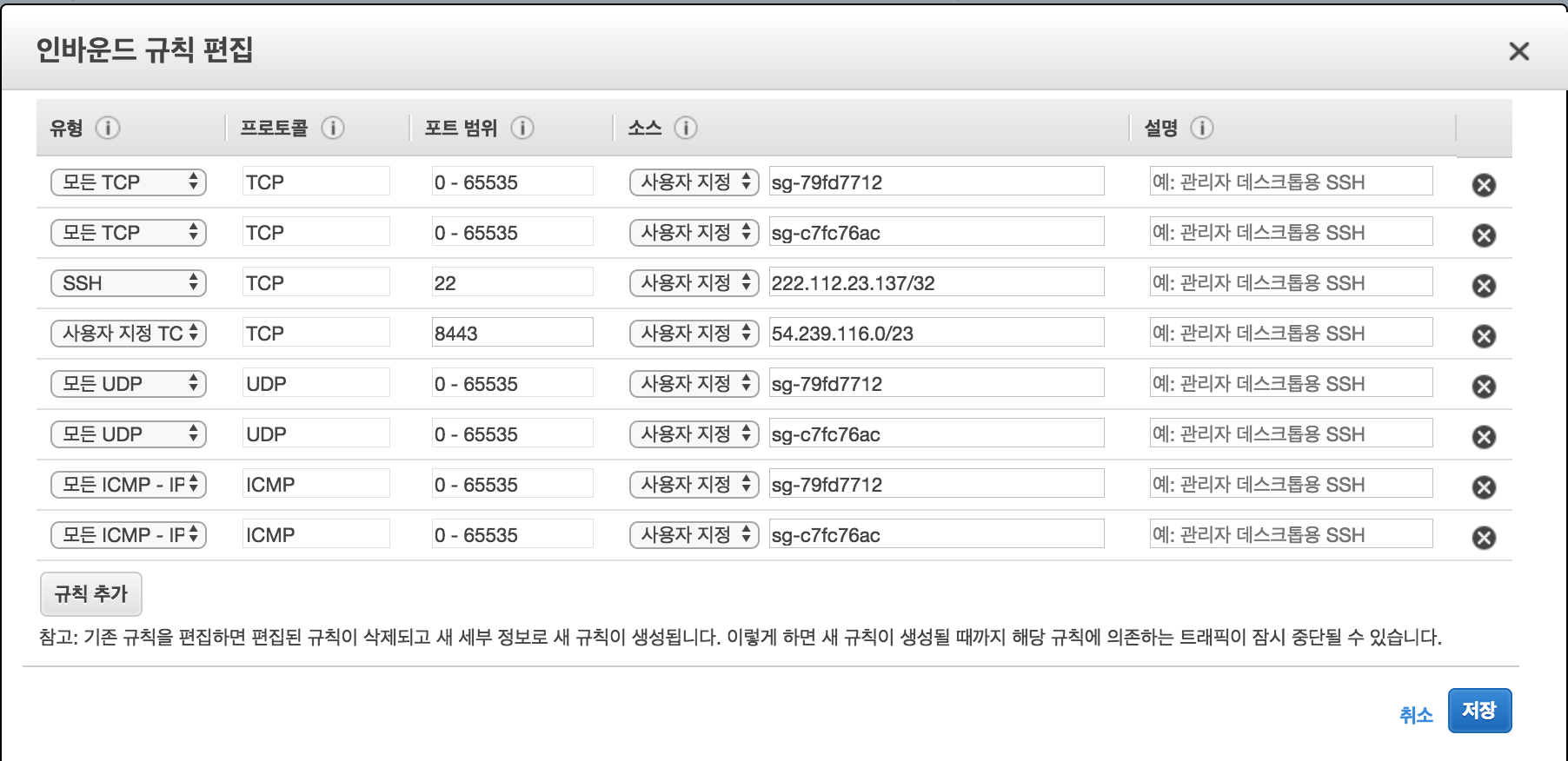
ssh 22 번 포트에 대해 내 IP 로 접속가능 하도록 인바운드를 세팅해준다. 이제 마스터 노드에서 코드를 받아 emr 에서 spark 를 돌려볼 준비가 됐다.
마스터 인스턴스 접속 후 세팅
$ ssh -i your_emr_key_pair.pem hadoop@master-ec2-ip
$ ssh -i ~/.ssh/keys/yaboong_keypair.pem hadoop@13.125.109.113
접속은 위와 같이 하면 된다. 이때 각자 EMR 을 생성할 때 지정했던 keypair 로 로그인하면되는데, 주의 할 점은 user 를 반드시 hadoop 으로 해야 한다. 보통 AWS EC2 인스턴스에 접속 할 때 ec2-user@ip 형태로 접속 하지만 EMR 의 경우 ec2-user 로 로그인 하면 실행시 권한 문제로 아래와 같은 에러가 발생한다.
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=ec2-user, access=WRITE, inode="/user/ec2-user/.sparkStaging/application_1516199149034_0004":hdfs:hadoop:drwxr-xr-x
접속하면 다음과 같이 까리한 EMR 이 나온다.
코드 받아와서 돌려보기
지금부터의 과정은 로컬 머신에서 하던 것과 거의 동일하므로 커맨드 위주로 적겠다.
git 설치
$ yum install git-core
sbt 설치
$ curl https://bintray.com/sbt/rpm/rpm | sudo tee /etc/yum.repos.d/bintray-sbt-rpm.repo
$ sudo yum install sbt
작업 디렉토리 만들고 코드 받아오기
$ cd ~
$ mkdir workspace
$ cd workspace
$ git clone https://github.com/yaboong/spark-study-project.git emr-spark-example
$ cd emr-spark-example
빌드
$ sbt assembly
sbt 최초 실행시, 필요한 라이브러리를 받아오기 때문에 시간이 좀 걸린다… 한참 걸린다… 제대로 끝나면 아래와 같은 로그가 나온다.
[info] Done packaging.
[success] Total time: 689 s, completed Jan 17, 2018 3:45:19 PM
Input File Upload
test_big_test.txt 파일이 있는 경로로 가서 sftp 로 master 인스턴스에 input 파일을 전송한다.
$ sftp -i ~/.ssh/keys/yaboong_keypair.pem hadoop@13.125.109.113
sftp> cd workspace/emr-spark-example/resource
sftp> put test_big_data.txt
sftp> exit
Run!
spark-submit --class com.yaboong.spark.SundayCount target/scala-2.11/spark-study-project-assembly-0.0.1.jar resource/test_big_data.txt
어라? 아래와 같은 에러가 난다.
Exception!
Exception in thread "main" org.apache.hadoop.mapred.InvalidInputException: Input path does not exist:
hdfs://ip-172-31-2-148.ap-northeast-2.compute.internal:8020/user/hadoop/test_big_data.txt
클라이언트 프로그램의 코드를 실제로 돌리는 4대의 인스턴스에서 test_big_data.txt 라는 input 파일을 찾을 수 없기 때문이다. 마스터 노드에만 sftp 로 파일을 전송 해 뒀기 때문에 워커 인스턴스 4대 에서는 저 파일을 찾을 수가 없다. 워커 인스턴스에서도 input 파일을 찾아 분산처리 할 수 있게 hadoop file system 에 파일을 배포 해 둬야 한다.
$ hdfs dfs -mkdir -p /user/hadoop
$ hdfs dfs -put ~/workspace/emr-spark-example/resource/test_big_data.txt /user/hadoop
다시 Run!
[hadoop@ip-172-31-2-148 emr-spark-example]$ spark-submit --class com.yaboong.spark.SundayCount target/scala-2.11/spark-study-project-assembly-0.0.1.jar test_big_data.txt
18/01/17 15:57:10 INFO SparkContext: Running Spark version 2.2.1
18/01/17 15:57:10 INFO SparkContext: Submitted application: com.yaboong.spark.SundayCount
18/01/17 15:57:10 INFO SecurityManager: Changing view acls to: hadoop
18/01/17 15:57:10 INFO SecurityManager: Changing modify acls to: hadoop
18/01/17 15:57:10 INFO SecurityManager: Changing view acls groups to:
18/01/17 15:57:10 INFO SecurityManager: Changing modify acls groups to:
18/01/17 15:57:10 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set()
18/01/17 15:57:11 INFO Utils: Successfully started service 'sparkDriver' on port 46839.
18/01/17 15:57:11 INFO SparkEnv: Registering MapOutputTracker
18/01/17 15:57:11 INFO SparkEnv: Registering BlockManagerMaster
18/01/17 15:57:11 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
18/01/17 15:57:11 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
18/01/17 15:57:11 INFO DiskBlockManager: Created local directory at /mnt/tmp/blockmgr-30e70e2a-6473-4d22-8306-144c8d93e842
18/01/17 15:57:11 INFO MemoryStore: MemoryStore started with capacity 12.3 GB
18/01/17 15:57:11 INFO SparkEnv: Registering OutputCommitCoordinator
18/01/17 15:57:11 INFO Utils: Successfully started service 'SparkUI' on port 4040.
18/01/17 15:57:11 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://ip-172-31-2-148.ap-northeast-2.compute.internal:4040
18/01/17 15:57:11 INFO SparkContext: Added JAR file:/home/hadoop/workspace/emr-spark-example/target/scala-2.11/spark-study-project-assembly-0.0.1.jar at spark://172.31.2.148:46839/jars/spark-study-project-assembly-0.0.1.jar with timestamp 1516204631767
18/01/17 15:57:12 INFO Utils: Using initial executors = 4, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances
18/01/17 15:57:13 INFO RMProxy: Connecting to ResourceManager at ip-172-31-2-148.ap-northeast-2.compute.internal/172.31.2.148:8032
18/01/17 15:57:13 INFO Client: Requesting a new application from cluster with 4 NodeManagers
18/01/17 15:57:13 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (23424 MB per container)
18/01/17 15:57:13 INFO Client: Will allocate AM container, with 896 MB memory including 384 MB overhead
18/01/17 15:57:13 INFO Client: Setting up container launch context for our AM
18/01/17 15:57:13 INFO Client: Setting up the launch environment for our AM container
18/01/17 15:57:13 INFO Client: Preparing resources for our AM container
18/01/17 15:57:15 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
18/01/17 15:57:17 INFO Client: Uploading resource file:/mnt/tmp/spark-32f08dca-614e-4f07-aed7-aa419a57d2f5/__spark_libs__947407334597124440.zip -> hdfs://ip-172-31-2-148.ap-northeast-2.compute.internal:8020/user/hadoop/.sparkStaging/application_1516199149034_0006/__spark_libs__947407334597124440.zip
18/01/17 15:57:18 INFO Client: Uploading resource file:/mnt/tmp/spark-32f08dca-614e-4f07-aed7-aa419a57d2f5/__spark_conf__4806259687623395312.zip -> hdfs://ip-172-31-2-148.ap-northeast-2.compute.internal:8020/user/hadoop/.sparkStaging/application_1516199149034_0006/__spark_conf__.zip
18/01/17 15:57:18 INFO SecurityManager: Changing view acls to: hadoop
18/01/17 15:57:18 INFO SecurityManager: Changing modify acls to: hadoop
18/01/17 15:57:18 INFO SecurityManager: Changing view acls groups to:
18/01/17 15:57:18 INFO SecurityManager: Changing modify acls groups to:
18/01/17 15:57:18 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set()
18/01/17 15:57:18 INFO Client: Submitting application application_1516199149034_0006 to ResourceManager
18/01/17 15:57:18 INFO YarnClientImpl: Submitted application application_1516199149034_0006
18/01/17 15:57:18 INFO SchedulerExtensionServices: Starting Yarn extension services with app application_1516199149034_0006 and attemptId None
18/01/17 15:57:19 INFO Client: Application report for application_1516199149034_0006 (state: ACCEPTED)
18/01/17 15:57:19 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1516204638420
final status: UNDEFINED
tracking URL: http://ip-172-31-2-148.ap-northeast-2.compute.internal:20888/proxy/application_1516199149034_0006/
user: hadoop
18/01/17 15:57:20 INFO Client: Application report for application_1516199149034_0006 (state: ACCEPTED)
18/01/17 15:57:21 INFO Client: Application report for application_1516199149034_0006 (state: ACCEPTED)
18/01/17 15:57:22 INFO Client: Application report for application_1516199149034_0006 (state: ACCEPTED)
18/01/17 15:57:22 INFO YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM)
18/01/17 15:57:22 INFO YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> ip-172-31-2-148.ap-northeast-2.compute.internal, PROXY_URI_BASES -> http://ip-172-31-2-148.ap-northeast-2.compute.internal:20888/proxy/application_1516199149034_0006), /proxy/application_1516199149034_0006
18/01/17 15:57:22 INFO JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
18/01/17 15:57:23 INFO Client: Application report for application_1516199149034_0006 (state: RUNNING)
18/01/17 15:57:23 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 172.31.7.136
ApplicationMaster RPC port: 0
queue: default
start time: 1516204638420
final status: UNDEFINED
tracking URL: http://ip-172-31-2-148.ap-northeast-2.compute.internal:20888/proxy/application_1516199149034_0006/
user: hadoop
18/01/17 15:57:23 INFO YarnClientSchedulerBackend: Application application_1516199149034_0006 has started running.
18/01/17 15:57:23 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 36927.
18/01/17 15:57:23 INFO NettyBlockTransferService: Server created on 172.31.2.148:36927
18/01/17 15:57:23 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
18/01/17 15:57:23 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 172.31.2.148, 36927, None)
18/01/17 15:57:23 INFO BlockManagerMasterEndpoint: Registering block manager 172.31.2.148:36927 with 12.3 GB RAM, BlockManagerId(driver, 172.31.2.148, 36927, None)
18/01/17 15:57:23 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 172.31.2.148, 36927, None)
18/01/17 15:57:23 INFO BlockManager: external shuffle service port = 7337
18/01/17 15:57:23 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 172.31.2.148, 36927, None)
18/01/17 15:57:23 INFO EventLoggingListener: Logging events to hdfs:///var/log/spark/apps/application_1516199149034_0006
18/01/17 15:57:23 INFO Utils: Using initial executors = 4, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances
18/01/17 15:57:26 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.31.7.136:37248) with ID 2
18/01/17 15:57:26 INFO ExecutorAllocationManager: New executor 2 has registered (new total is 1)
18/01/17 15:57:26 INFO BlockManagerMasterEndpoint: Registering block manager ip-172-31-7-136.ap-northeast-2.compute.internal:39551 with 11.8 GB RAM, BlockManagerId(2, ip-172-31-7-136.ap-northeast-2.compute.internal, 39551, None)
18/01/17 15:57:27 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.31.9.233:42352) with ID 1
18/01/17 15:57:27 INFO ExecutorAllocationManager: New executor 1 has registered (new total is 2)
18/01/17 15:57:27 INFO BlockManagerMasterEndpoint: Registering block manager ip-172-31-9-233.ap-northeast-2.compute.internal:45545 with 11.8 GB RAM, BlockManagerId(1, ip-172-31-9-233.ap-northeast-2.compute.internal, 45545, None)
18/01/17 15:57:28 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.31.5.132:43118) with ID 4
18/01/17 15:57:28 INFO ExecutorAllocationManager: New executor 4 has registered (new total is 3)
18/01/17 15:57:28 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.31.12.193:57614) with ID 3
18/01/17 15:57:28 INFO ExecutorAllocationManager: New executor 3 has registered (new total is 4)
18/01/17 15:57:28 INFO BlockManagerMasterEndpoint: Registering block manager ip-172-31-5-132.ap-northeast-2.compute.internal:36915 with 11.8 GB RAM, BlockManagerId(4, ip-172-31-5-132.ap-northeast-2.compute.internal, 36915, None)
18/01/17 15:57:28 INFO YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8
18/01/17 15:57:28 INFO BlockManagerMasterEndpoint: Registering block manager ip-172-31-12-193.ap-northeast-2.compute.internal:36237 with 11.8 GB RAM, BlockManagerId(3, ip-172-31-12-193.ap-northeast-2.compute.internal, 36237, None)
18/01/17 15:57:28 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 310.1 KB, free 12.3 GB)
18/01/17 15:57:28 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 26.2 KB, free 12.3 GB)
18/01/17 15:57:28 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 172.31.2.148:36927 (size: 26.2 KB, free: 12.3 GB)
18/01/17 15:57:28 INFO SparkContext: Created broadcast 0 from textFile at SundayCount.scala:22
18/01/17 15:57:28 INFO GPLNativeCodeLoader: Loaded native gpl library
18/01/17 15:57:28 INFO LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev fc548a0642e795113789414490c9e59e6a8b91e4]
18/01/17 15:57:28 INFO FileInputFormat: Total input paths to process : 1
18/01/17 15:57:28 INFO SparkContext: Starting job: count at SundayCount.scala:33
18/01/17 15:57:28 INFO DAGScheduler: Got job 0 (count at SundayCount.scala:33) with 12 output partitions
18/01/17 15:57:28 INFO DAGScheduler: Final stage: ResultStage 0 (count at SundayCount.scala:33)
18/01/17 15:57:28 INFO DAGScheduler: Parents of final stage: List()
18/01/17 15:57:28 INFO DAGScheduler: Missing parents: List()
18/01/17 15:57:28 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[3] at filter at SundayCount.scala:29), which has no missing parents
18/01/17 15:57:29 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 3.6 KB, free 12.3 GB)
18/01/17 15:57:29 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.1 KB, free 12.3 GB)
18/01/17 15:57:29 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 172.31.2.148:36927 (size: 2.1 KB, free: 12.3 GB)
18/01/17 15:57:29 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1047
18/01/17 15:57:29 INFO DAGScheduler: Submitting 12 missing tasks from ResultStage 0 (MapPartitionsRDD[3] at filter at SundayCount.scala:29) (first 15 tasks are for partitions Vector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11))
18/01/17 15:57:29 INFO YarnScheduler: Adding task set 0.0 with 12 tasks
18/01/17 15:57:29 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, ip-172-31-5-132.ap-northeast-2.compute.internal, executor 4, partition 0, NODE_LOCAL, 4919 bytes)
18/01/17 15:57:29 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, ip-172-31-7-136.ap-northeast-2.compute.internal, executor 2, partition 1, NODE_LOCAL, 4919 bytes)
18/01/17 15:57:29 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, ip-172-31-12-193.ap-northeast-2.compute.internal, executor 3, partition 2, NODE_LOCAL, 4919 bytes)
18/01/17 15:57:29 INFO TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3, ip-172-31-9-233.ap-northeast-2.compute.internal, executor 1, partition 3, NODE_LOCAL, 4919 bytes)
18/01/17 15:57:29 INFO TaskSetManager: Starting task 5.0 in stage 0.0 (TID 4, ip-172-31-5-132.ap-northeast-2.compute.internal, executor 4, partition 5, NODE_LOCAL, 4919 bytes)
18/01/17 15:57:29 INFO TaskSetManager: Starting task 4.0 in stage 0.0 (TID 5, ip-172-31-7-136.ap-northeast-2.compute.internal, executor 2, partition 4, NODE_LOCAL, 4919 bytes)
18/01/17 15:57:29 INFO TaskSetManager: Starting task 6.0 in stage 0.0 (TID 6, ip-172-31-12-193.ap-northeast-2.compute.internal, executor 3, partition 6, NODE_LOCAL, 4919 bytes)
18/01/17 15:57:29 INFO TaskSetManager: Starting task 8.0 in stage 0.0 (TID 7, ip-172-31-9-233.ap-northeast-2.compute.internal, executor 1, partition 8, NODE_LOCAL, 4919 bytes)
18/01/17 15:57:29 INFO TaskSetManager: Starting task 7.0 in stage 0.0 (TID 8, ip-172-31-5-132.ap-northeast-2.compute.internal, executor 4, partition 7, NODE_LOCAL, 4919 bytes)
18/01/17 15:57:29 INFO TaskSetManager: Starting task 11.0 in stage 0.0 (TID 9, ip-172-31-7-136.ap-northeast-2.compute.internal, executor 2, partition 11, NODE_LOCAL, 4919 bytes)
18/01/17 15:57:29 INFO TaskSetManager: Starting task 9.0 in stage 0.0 (TID 10, ip-172-31-12-193.ap-northeast-2.compute.internal, executor 3, partition 9, NODE_LOCAL, 4919 bytes)
18/01/17 15:57:29 INFO TaskSetManager: Starting task 10.0 in stage 0.0 (TID 11, ip-172-31-5-132.ap-northeast-2.compute.internal, executor 4, partition 10, NODE_LOCAL, 4919 bytes)
18/01/17 15:57:29 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on ip-172-31-7-136.ap-northeast-2.compute.internal:39551 (size: 2.1 KB, free: 11.8 GB)
18/01/17 15:57:29 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on ip-172-31-5-132.ap-northeast-2.compute.internal:36915 (size: 2.1 KB, free: 11.8 GB)
18/01/17 15:57:29 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on ip-172-31-12-193.ap-northeast-2.compute.internal:36237 (size: 2.1 KB, free: 11.8 GB)
18/01/17 15:57:29 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on ip-172-31-9-233.ap-northeast-2.compute.internal:45545 (size: 2.1 KB, free: 11.8 GB)
18/01/17 15:57:29 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on ip-172-31-7-136.ap-northeast-2.compute.internal:39551 (size: 26.2 KB, free: 11.8 GB)
18/01/17 15:57:29 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on ip-172-31-5-132.ap-northeast-2.compute.internal:36915 (size: 26.2 KB, free: 11.8 GB)
18/01/17 15:57:29 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on ip-172-31-9-233.ap-northeast-2.compute.internal:45545 (size: 26.2 KB, free: 11.8 GB)
18/01/17 15:57:29 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on ip-172-31-12-193.ap-northeast-2.compute.internal:36237 (size: 26.2 KB, free: 11.8 GB)
18/01/17 15:57:41 INFO TaskSetManager: Finished task 8.0 in stage 0.0 (TID 7) in 12717 ms on ip-172-31-9-233.ap-northeast-2.compute.internal (executor 1) (1/12)
18/01/17 15:57:41 INFO TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 12864 ms on ip-172-31-9-233.ap-northeast-2.compute.internal (executor 1) (2/12)
18/01/17 15:57:42 INFO TaskSetManager: Finished task 11.0 in stage 0.0 (TID 9) in 13884 ms on ip-172-31-7-136.ap-northeast-2.compute.internal (executor 2) (3/12)
18/01/17 15:57:44 INFO TaskSetManager: Finished task 4.0 in stage 0.0 (TID 5) in 15774 ms on ip-172-31-7-136.ap-northeast-2.compute.internal (executor 2) (4/12)
18/01/17 15:57:45 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 16021 ms on ip-172-31-7-136.ap-northeast-2.compute.internal (executor 2) (5/12)
18/01/17 15:57:45 INFO TaskSetManager: Finished task 6.0 in stage 0.0 (TID 6) in 16402 ms on ip-172-31-12-193.ap-northeast-2.compute.internal (executor 3) (6/12)
18/01/17 15:57:45 INFO TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 16779 ms on ip-172-31-12-193.ap-northeast-2.compute.internal (executor 3) (7/12)
18/01/17 15:57:46 INFO TaskSetManager: Finished task 9.0 in stage 0.0 (TID 10) in 17198 ms on ip-172-31-12-193.ap-northeast-2.compute.internal (executor 3) (8/12)
18/01/17 15:57:49 INFO TaskSetManager: Finished task 5.0 in stage 0.0 (TID 4) in 20188 ms on ip-172-31-5-132.ap-northeast-2.compute.internal (executor 4) (9/12)
18/01/17 15:57:49 INFO TaskSetManager: Finished task 7.0 in stage 0.0 (TID 8) in 20657 ms on ip-172-31-5-132.ap-northeast-2.compute.internal (executor 4) (10/12)
18/01/17 15:57:49 INFO TaskSetManager: Finished task 10.0 in stage 0.0 (TID 11) in 20841 ms on ip-172-31-5-132.ap-northeast-2.compute.internal (executor 4) (11/12)
18/01/17 15:57:50 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 21219 ms on ip-172-31-5-132.ap-northeast-2.compute.internal (executor 4) (12/12)
18/01/17 15:57:50 INFO YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
18/01/17 15:57:50 INFO DAGScheduler: ResultStage 0 (count at SundayCount.scala:33) finished in 21.225 s
18/01/17 15:57:50 INFO DAGScheduler: Job 0 finished: count at SundayCount.scala:33, took 21.421852 s
주어진 데이터에는 일요일이 25040000개 들어 있습니다
18/01/17 15:57:50 INFO SparkUI: Stopped Spark web UI at http://ip-172-31-2-148.ap-northeast-2.compute.internal:4040
18/01/17 15:57:50 INFO YarnClientSchedulerBackend: Interrupting monitor thread
18/01/17 15:57:50 INFO YarnClientSchedulerBackend: Shutting down all executors
18/01/17 15:57:50 INFO YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
18/01/17 15:57:50 INFO SchedulerExtensionServices: Stopping SchedulerExtensionServices
(serviceOption=None,
services=List(),
started=false)
18/01/17 15:57:50 INFO YarnClientSchedulerBackend: Stopped
18/01/17 15:57:50 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
18/01/17 15:57:50 INFO MemoryStore: MemoryStore cleared
18/01/17 15:57:50 INFO BlockManager: BlockManager stopped
18/01/17 15:57:50 INFO BlockManagerMaster: BlockManagerMaster stopped
18/01/17 15:57:50 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
18/01/17 15:57:50 INFO SparkContext: Successfully stopped SparkContext
18/01/17 15:57:50 INFO ShutdownHookManager: Shutdown hook called
18/01/17 15:57:50 INFO ShutdownHookManager: Deleting directory /mnt/tmp/spark-32f08dca-614e-4f07-aed7-aa419a57d2f5
[hadoop@ip-172-31-2-148 emr-spark-example]$
역시나 이 많은 로그들이 다 무슨 이야기를 하는 것인지는 차근차근 공부해 나가야겠다. 일단 결과만 보면
18/01/17 15:57:50 INFO DAGScheduler: Job 0 finished: count at SundayCount.scala:33, took 21.421852 s
주어진 데이터에는 일요일이 25040000개 들어 있습니다
제대로 카운트를 했고, 소요시간은 21초가 걸렸다.
Spark 를 사용하지 않고, 단순 스크립트로 돌렸을 때 약 54분 (3240초)
Spark 를 사용하고, 로컬에서 standalone 으로 돌렸을 때 약 98초
Spark 를 사용하고, AWS EMR 로 1대의 마스터 4대의 워커 노드로 분산처리 했을 때는 약 21초
총 5대의 ec2 instance 를 이용해서 돌렸지만 이걸 50대로 늘린다고 해도 네트워크에 소모되는 시간, 최적화를 위한 시간 등 준비시간이 있기 때문에 1초만에 끝나지는 않는다. 하지만 TB 단위의 입력 데이터를 수십대의 인스턴스로 spark 를 돌리면 진짜 위력을 볼 수 있을 것 같다.
이 정도면 spark 로 hello world 찍기는 나름 열심히 한 것 같다. 이거 하려고.. 얼마나 삽질을 많이 했는지.. 힘들었다.. 근데 재밌다!!!! 신기하다!!!