
Spark 시작하기 1.2 - 좀 더 큰 데이터 처리해보기 & 성능비교
소스 받기
$ git pull https://github.com/yaboong/spark-study-project.git
개요
이전 포스팅 에서 %Y%m%d (20171210) 형식의 date string 을 가진 .txt 파일을 input 으로 받아 일요일이 몇개 있는지 알아내는 코드를 짰다. 이 코드를 똑같이 사용하고, 총 175,310,001 (약 1억 7천 5백만) 개의 lines, 1.58 GB 크기로 이루어진 .txt 파일을 input 으로 받아서 일요일이 몇개 있는지 찾아 볼 것이다. 똑같이 local machine 에서 standalone 으로 돌려 볼 것이며, 같은 작업을 python script 로 돌렸을 때와 시간이 얼마나 차이 나는지 살펴 볼 것이다. python 과 scala 를 비교하거나 하는 것이 아니라, spark 를 어설프게라도 사용할 때와 사용하지 않을 때의 비교를 해 보는 것이다. 단순한 배치 스크립트를 짤 때 python 을 많이 사용했었기 때문에, 단순한 방식으로 처리할 때와 spark 라는 엔진을 사용해서 처리할 때의 성능비교를 해 보았다.
Simple Script
말 그대로 정말 단순하게 처리하는 방법이다. line by line 으로 한 줄 씩 값을 읽어와서 date 오브젝트로 변환 후 일요일이면 카운트 1 올리고 아니면 넘어간다.
sunday_count.py
from datetime import datetime
import calendar
start_time = datetime.now()
print(f'start time: {start_time}')
with open('/Users/yaboong/test_big_data.txt', 'r') as f:
lines = f.readlines()
sunday_cnt = 0
for line in lines:
line_value = line.strip()
date = datetime.strptime(line_value, '%Y%m%d')
weekday = date.weekday()
sunday_cnt = sunday_cnt + 1 if calendar.day_name[weekday] == 'Sunday' else sunday_cnt
end_time = datetime.now()
print(f'end time: {end_time}')
print(f'SUNDAY COUNT: {sunday_cnt}')
print(f'elapsed time: {end_time - start_time}')
Simple Script 실행결과
다른 로그는 딱히 남긴게 없기 때문에 일요일 갯수, 시작시간, 종료시간, 경과시간 정도만 출력해 보았다.
start time: 2018-01-01 22:40:04.362794
end time: 2018-01-01 23:34:53.773569
elapsed time: 0:54:49.410775
SUNDAY COUNT: 25040000
Process finished with exit code 0
주어진 input 파일에는 25,040,000 개의 일요일이 있고, 54분 49초가 걸렸다.
Spark 로 돌려보기
이번에는 같은 데이터를 가지고 spark 를 이용해서 돌려보았다. 아래는 그 로그인데 좀 길다.
MacBook-Pro-3:spark-study-project yaboong$ spark-submit --master local --class com.yaboong.spark.SundayCount target/scala-2.11/spark-study-project-assembly-0.0.1.jar resource/test_big_data.txt
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
18/01/17 22:21:06 INFO SparkContext: Running Spark version 2.2.0
18/01/17 22:21:07 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/01/17 22:21:07 INFO SparkContext: Submitted application: com.yaboong.spark.SundayCount
18/01/17 22:21:07 INFO SecurityManager: Changing view acls to: yaboong
18/01/17 22:21:07 INFO SecurityManager: Changing modify acls to: yaboong
18/01/17 22:21:07 INFO SecurityManager: Changing view acls groups to:
18/01/17 22:21:07 INFO SecurityManager: Changing modify acls groups to:
18/01/17 22:21:07 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(yaboong); groups with view permissions: Set(); users with modify permissions: Set(yaboong); groups with modify permissions: Set()
18/01/17 22:21:07 INFO Utils: Successfully started service 'sparkDriver' on port 49531.
18/01/17 22:21:07 INFO SparkEnv: Registering MapOutputTracker
18/01/17 22:21:07 INFO SparkEnv: Registering BlockManagerMaster
18/01/17 22:21:07 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
18/01/17 22:21:07 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
18/01/17 22:21:07 INFO DiskBlockManager: Created local directory at /private/var/folders/mz/7nk42g591rzd1v3x18ln5jpm0000gn/T/blockmgr-caccb67d-7515-49e9-a020-8e7678621718
18/01/17 22:21:07 INFO MemoryStore: MemoryStore started with capacity 366.3 MB
18/01/17 22:21:07 INFO SparkEnv: Registering OutputCommitCoordinator
18/01/17 22:21:07 INFO Utils: Successfully started service 'SparkUI' on port 4040.
18/01/17 22:21:07 INFO SparkUI: Bound SparkUI to 127.0.0.1, and started at http://127.0.0.1:4040
18/01/17 22:21:07 INFO SparkContext: Added JAR file:/Users/yaboong/DevWorkspace/etc-workspace/spark-study-project/target/scala-2.11/spark-study-project-assembly-0.0.1.jar at spark://127.0.0.1:49531/jars/spark-study-project-assembly-0.0.1.jar with timestamp 1516195267795
18/01/17 22:21:07 INFO Executor: Starting executor ID driver on host localhost
18/01/17 22:21:07 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 49532.
18/01/17 22:21:07 INFO NettyBlockTransferService: Server created on 127.0.0.1:49532
18/01/17 22:21:07 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
18/01/17 22:21:07 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 127.0.0.1, 49532, None)
18/01/17 22:21:07 INFO BlockManagerMasterEndpoint: Registering block manager 127.0.0.1:49532 with 366.3 MB RAM, BlockManagerId(driver, 127.0.0.1, 49532, None)
18/01/17 22:21:07 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 127.0.0.1, 49532, None)
18/01/17 22:21:07 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 127.0.0.1, 49532, None)
18/01/17 22:21:08 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 236.5 KB, free 366.1 MB)
18/01/17 22:21:08 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 22.9 KB, free 366.0 MB)
18/01/17 22:21:08 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 127.0.0.1:49532 (size: 22.9 KB, free: 366.3 MB)
18/01/17 22:21:08 INFO SparkContext: Created broadcast 0 from textFile at SundayCount.scala:22
18/01/17 22:21:08 INFO FileInputFormat: Total input paths to process : 1
18/01/17 22:21:08 INFO SparkContext: Starting job: count at SundayCount.scala:33
18/01/17 22:21:08 INFO DAGScheduler: Got job 0 (count at SundayCount.scala:33) with 47 output partitions
18/01/17 22:21:08 INFO DAGScheduler: Final stage: ResultStage 0 (count at SundayCount.scala:33)
18/01/17 22:21:08 INFO DAGScheduler: Parents of final stage: List()
18/01/17 22:21:08 INFO DAGScheduler: Missing parents: List()
18/01/17 22:21:08 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[3] at filter at SundayCount.scala:29), which has no missing parents
18/01/17 22:21:08 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 3.5 KB, free 366.0 MB)
18/01/17 22:21:08 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.1 KB, free 366.0 MB)
18/01/17 22:21:08 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 127.0.0.1:49532 (size: 2.1 KB, free: 366.3 MB)
18/01/17 22:21:08 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1006
18/01/17 22:21:08 INFO DAGScheduler: Submitting 47 missing tasks from ResultStage 0 (MapPartitionsRDD[3] at filter at SundayCount.scala:29) (first 15 tasks are for partitions Vector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14))
18/01/17 22:21:08 INFO TaskSchedulerImpl: Adding task set 0.0 with 47 tasks
18/01/17 22:21:08 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 4912 bytes)
18/01/17 22:21:08 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
18/01/17 22:21:08 INFO Executor: Fetching spark://127.0.0.1:49531/jars/spark-study-project-assembly-0.0.1.jar with timestamp 1516195267795
18/01/17 22:21:08 INFO TransportClientFactory: Successfully created connection to /127.0.0.1:49531 after 29 ms (0 ms spent in bootstraps)
18/01/17 22:21:08 INFO Utils: Fetching spark://127.0.0.1:49531/jars/spark-study-project-assembly-0.0.1.jar to /private/var/folders/mz/7nk42g591rzd1v3x18ln5jpm0000gn/T/spark-8467543b-cb63-491c-adf4-5a07a926df51/userFiles-9651dced-2f2a-4a48-b0e5-706b6d6bd3bd/fetchFileTemp3469161257925128469.tmp
18/01/17 22:21:08 INFO Executor: Adding file:/private/var/folders/mz/7nk42g591rzd1v3x18ln5jpm0000gn/T/spark-8467543b-cb63-491c-adf4-5a07a926df51/userFiles-9651dced-2f2a-4a48-b0e5-706b6d6bd3bd/spark-study-project-assembly-0.0.1.jar to class loader
18/01/17 22:21:09 INFO HadoopRDD: Input split: file:/Users/yaboong/DevWorkspace/etc-workspace/spark-study-project/resource/test_big_data.txt:0+33554432
18/01/17 22:21:11 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 875 bytes result sent to driver
18/01/17 22:21:11 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 4912 bytes)
18/01/17 22:21:11 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
18/01/17 22:21:11 INFO HadoopRDD: Input split: file:/Users/yaboong/DevWorkspace/etc-workspace/spark-study-project/resource/test_big_data.txt:33554432+33554432
18/01/17 22:21:11 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 2647 ms on localhost (executor driver) (1/47)
18/01/17 22:21:13 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 875 bytes result sent to driver
18/01/17 22:21:13 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, localhost, executor driver, partition 2, PROCESS_LOCAL, 4912 bytes)
18/01/17 22:21:13 INFO Executor: Running task 2.0 in stage 0.0 (TID 2)
18/01/17 22:21:13 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 1957 ms on localhost (executor driver) (2/47)
18/01/17 22:21:13 INFO HadoopRDD: Input split: file:/Users/yaboong/DevWorkspace/etc-workspace/spark-study-project/resource/test_big_data.txt:67108864+33554432
18/01/17 22:21:15 INFO Executor: Finished task 2.0 in stage 0.0 (TID 2). 875 bytes result sent to driver
18/01/17 22:21:15 INFO TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3, localhost, executor driver, partition 3, PROCESS_LOCAL, 4912 bytes)
18/01/17 22:21:15 INFO Executor: Running task 3.0 in stage 0.0 (TID 3)
18/01/17 22:21:15 INFO TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 1964 ms on localhost (executor driver) (3/47)
18/01/17 22:21:15 INFO HadoopRDD: Input split: file:/Users/yaboong/DevWorkspace/etc-workspace/spark-study-project/resource/test_big_data.txt:100663296+33554432
18/01/17 22:21:17 INFO Executor: Finished task 3.0 in stage 0.0 (TID 3). 875 bytes result sent to driver
18/01/17 22:21:17 INFO TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4, localhost, executor driver, partition 4, PROCESS_LOCAL, 4912 bytes)
18/01/17 22:21:17 INFO Executor: Running task 4.0 in stage 0.0 (TID 4)
18/01/17 22:21:17 INFO TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 2054 ms on localhost (executor driver) (4/47)
18/01/17 22:21:17 INFO HadoopRDD: Input split: file:/Users/yaboong/DevWorkspace/etc-workspace/spark-study-project/resource/test_big_data.txt:134217728+33554432
18/01/17 22:21:19 INFO Executor: Finished task 4.0 in stage 0.0 (TID 4). 875 bytes result sent to driver
18/01/17 22:21:19 INFO TaskSetManager: Starting task 5.0 in stage 0.0 (TID 5, localhost, executor driver, partition 5, PROCESS_LOCAL, 4912 bytes)
18/01/17 22:21:19 INFO Executor: Running task 5.0 in stage 0.0 (TID 5)
18/01/17 22:21:19 INFO TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 2089 ms on localhost (executor driver) (5/47)
18/01/17 22:21:19 INFO HadoopRDD: Input split: file:/Users/yaboong/DevWorkspace/etc-workspace/spark-study-project/resource/test_big_data.txt:167772160+33554432
18/01/17 22:21:21 INFO Executor: Finished task 5.0 in stage 0.0 (TID 5). 875 bytes result sent to driver
18/01/17 22:21:21 INFO TaskSetManager: Starting task 6.0 in stage 0.0 (TID 6, localhost, executor driver, partition 6, PROCESS_LOCAL, 4912 bytes)
... TID 7 ~ TID 42 까지는 생략..
.
.
.
18/01/17 22:22:40 INFO TaskSetManager: Finished task 43.0 in stage 0.0 (TID 43) in 2097 ms on localhost (executor driver) (44/47)
18/01/17 22:22:40 INFO HadoopRDD: Input split: file:/Users/yaboong/DevWorkspace/etc-workspace/spark-study-project/resource/test_big_data.txt:1476395008+33554432
18/01/17 22:22:42 INFO Executor: Finished task 44.0 in stage 0.0 (TID 44). 875 bytes result sent to driver
18/01/17 22:22:42 INFO TaskSetManager: Starting task 45.0 in stage 0.0 (TID 45, localhost, executor driver, partition 45, PROCESS_LOCAL, 4912 bytes)
18/01/17 22:22:42 INFO Executor: Running task 45.0 in stage 0.0 (TID 45)
18/01/17 22:22:42 INFO TaskSetManager: Finished task 44.0 in stage 0.0 (TID 44) in 2119 ms on localhost (executor driver) (45/47)
18/01/17 22:22:42 INFO HadoopRDD: Input split: file:/Users/yaboong/DevWorkspace/etc-workspace/spark-study-project/resource/test_big_data.txt:1509949440+33554432
18/01/17 22:22:44 INFO Executor: Finished task 45.0 in stage 0.0 (TID 45). 875 bytes result sent to driver
18/01/17 22:22:44 INFO TaskSetManager: Starting task 46.0 in stage 0.0 (TID 46, localhost, executor driver, partition 46, PROCESS_LOCAL, 4912 bytes)
18/01/17 22:22:44 INFO Executor: Running task 46.0 in stage 0.0 (TID 46)
18/01/17 22:22:44 INFO TaskSetManager: Finished task 45.0 in stage 0.0 (TID 45) in 2039 ms on localhost (executor driver) (46/47)
18/01/17 22:22:44 INFO HadoopRDD: Input split: file:/Users/yaboong/DevWorkspace/etc-workspace/spark-study-project/resource/test_big_data.txt:1543503872+34286128
18/01/17 22:22:46 INFO Executor: Finished task 46.0 in stage 0.0 (TID 46). 875 bytes result sent to driver
18/01/17 22:22:46 INFO TaskSetManager: Finished task 46.0 in stage 0.0 (TID 46) in 2143 ms on localhost (executor driver) (47/47)
18/01/17 22:22:46 INFO DAGScheduler: ResultStage 0 (count at SundayCount.scala:33) finished in 98.065 s
18/01/17 22:22:46 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
18/01/17 22:22:46 INFO DAGScheduler: Job 0 finished: count at SundayCount.scala:33, took 98.203385 s
주어진 데이터에는 일요일이 25040000개 들어 있습니다
18/01/17 22:22:46 INFO SparkUI: Stopped Spark web UI at http://127.0.0.1:4040
18/01/17 22:22:46 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
18/01/17 22:22:46 INFO MemoryStore: MemoryStore cleared
18/01/17 22:22:46 INFO BlockManager: BlockManager stopped
18/01/17 22:22:46 INFO BlockManagerMaster: BlockManagerMaster stopped
18/01/17 22:22:46 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
18/01/17 22:22:46 INFO SparkContext: Successfully stopped SparkContext
18/01/17 22:22:46 INFO ShutdownHookManager: Shutdown hook called
18/01/17 22:22:46 INFO ShutdownHookManager: Deleting directory /private/var/folders/mz/7nk42g591rzd1v3x18ln5jpm0000gn/T/spark-8467543b-cb63-491c-adf4-5a07a926df51
Spark 실행 결과
저 많은 로그들이 다 무엇을 의미하는지는 차근차근 공부해 봐야겠다. 초짜 입장에서 재밌는 점 두 가지를 발견했는데 첫 번째는 그 실행 결과다.
18/01/17 22:22:46 INFO DAGScheduler: Job 0 finished: count at SundayCount.scala:33, took 98.203385 s
단순하게 하나씩 불러다가 카운트 했을 때 무려 54분이 걸렸는데 멀티 클러스터링을 한 것도 아니고, local machine 에서 standalone 으로 돌렸는데, spark 를 사용한 것 만으로 98 초로 실행 시간이 줄어들었다.
또 하나 재미있는 것은 이 부분이다.
18/01/17 22:21:07 INFO Utils: Successfully started service 'SparkUI' on port 4040.
18/01/17 22:21:07 INFO SparkUI: Bound SparkUI to 127.0.0.1, and started at http://127.0.0.1:4040
시키지도 않았는데 뭔 UI 를 시작했단다. 궁금해서 http://127.0.0.1:4040 로 들어가 보니 아래와 같이
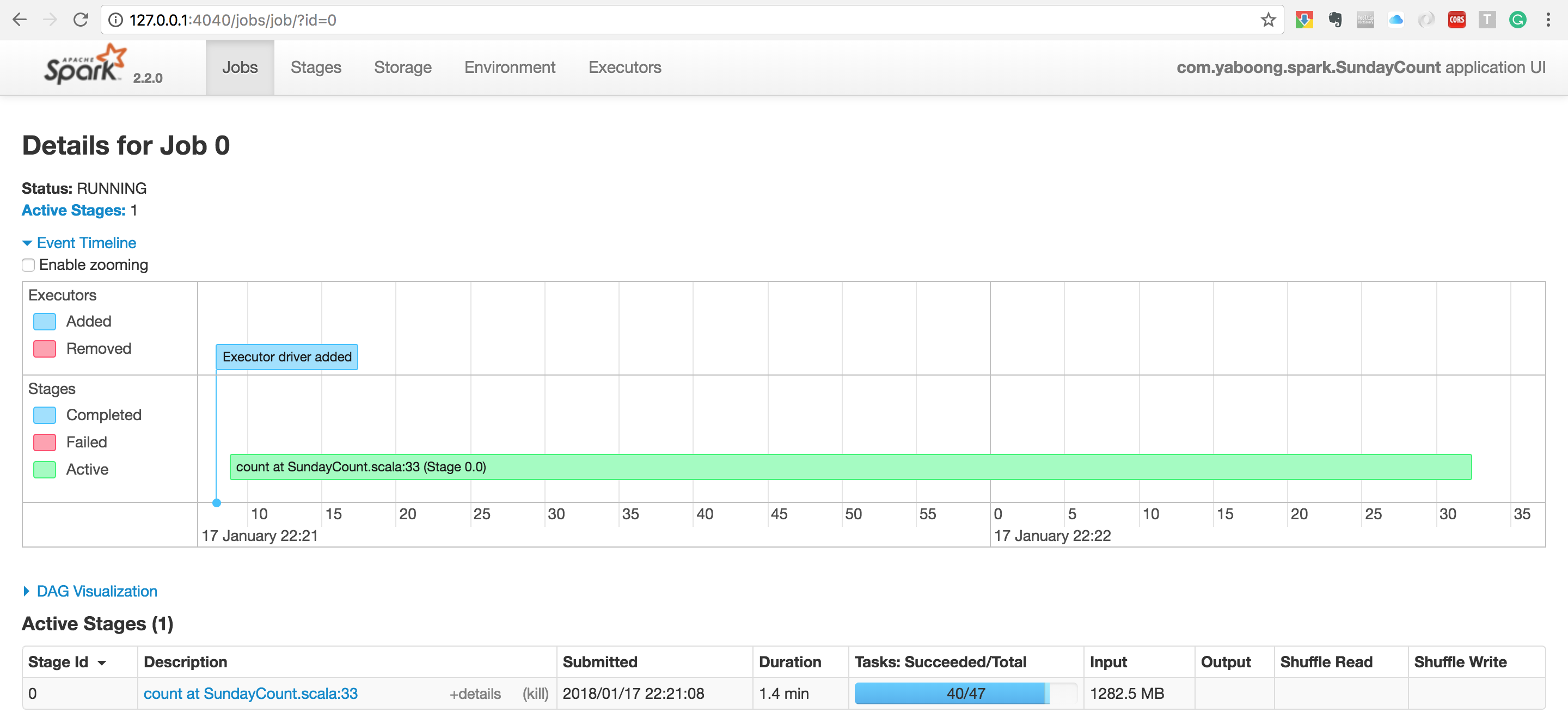
모니터링 할 수 있는 UI 를 제공한다. spark 가 돌고 있는 동안에만 접속 가능하다. 지금까지는 로컬에서 standalone 으로만 돌려봤는데 다음 번에는 AWS EMR(Elastic Map Reduce) 를 사용해서 같은 코드를 멀티 클러스터링으로 분산처리 해서 돌려볼 것이다.