Binary Search Tree (BST) - Java
개요
- Binary Search Tree (BST) 개요
- 삽입, 탐색, 순회, 삭제 구현 - Java
- 전체 코드 보기
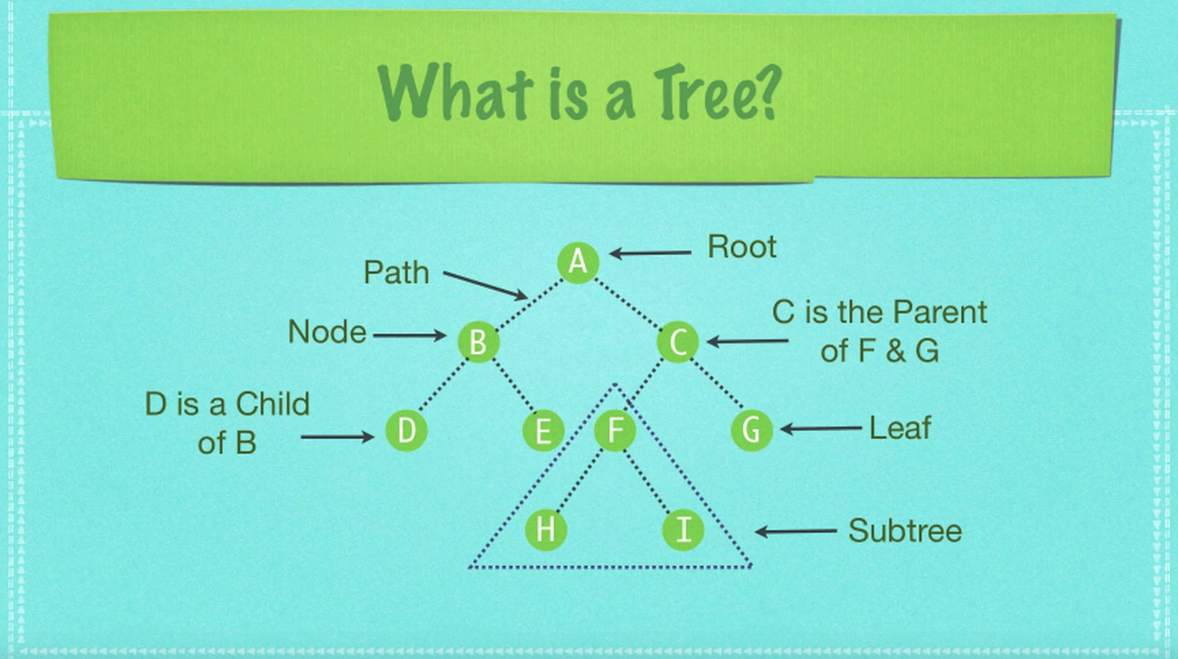
Tree 란
아래와 같은 모양을 가지는 데이터 구조다. 아래 그림은 이진트리이지만 자식 노드는 여러개가 되어도 상관없다. 다만 Binary Search Tree (BST) 에는 이름 그대로 이진트리 형태로 구성된다.
BST 에서는 root 보다 큰 노드는 오른쪽으로, 작은 노드는 왼쪽으로 가게 되는데, 만약 정렬된 데이터를 순차적으로 BST 에 삽입하게 된다면 사향트리가 된다. 그러면 Linked List 와 똑같은 형태가 되어 트리의 장점을 취하기 어렵다.
Tree 를 사용하는 이유
- 탐색, 삽입, 삭제가 빠르다
- 정렬 된 배열에서는 삽입, 삭제 작업이 비효율적이다
- 링크드 리스트는 검색이 느리다
- 평균적으로 O(log n) 의 시간복잡도를 가진다
Binary Search Tree 란
- 각 노드에 값이 있다.
- 각 노드의 키값은 모두 달라야 한다.
- 값들은 전순서가 있다.
- 노드의 왼쪽 서브트리에는 그 노드의 값보다 작은 값들을 지닌 노드들로 이루어져 있다.
- 노드의 오른쪽 서브트리에는 그 노드의 값보다 큰 값들을 지닌 노드들로 이루어져 있다.
- 좌우 하위 트리는 각각이 다시 이진 탐색 트리여야 한다.
- 중복된 노드가 없어야 한다.
위 리스트는 위키에 있는 이진탐색트리에 대한 설명인데 한 가지 의문점은 왜 중복이 없어야 하는가인데… 검색을 목적으로 하는 자료구조이기 때문에 중복이 많을 수 있는 경우 굳이 트리에 중복노드를 삽입해서 검색 속도를 느리게 할 필요가 없기 때문이다. 굳이 중복을 허용하는 이진탐색트리를 만들 필요가 있을까? 합당한 이유가 있다면 굳이 중복된 노드를 트리에 삽입하는 것 보다는 노드에 count 값을 가지게 하는 것으로 처리하는 게 효율적이라고 생각한다.
이 포스팅은 이 영상 을 가장 많이 참고했는데, 이 영상에서도 중복 노드가 있을 경우 삽입하지 않도록 하는 부분은 없어서 내가 코드를 조금 수정했다. (위키에 있는게 정답은 아니기 때문에) 내 개인적인 생각으로 이진탐색트리가 필수적으로 중복이 없어야 하는 자료구조는 아닌 것 같다. 다만 중복이 없어야 검색의 효율을 높일 수 있을 뿐.
BST 구현 - Java
삽입
삽입은 간단하다. 기존의 트리를 root 부터 삽입하려는 노드와 비교하면서 트리의 끝까지 내려간다. 비교하는 과정에서 BST 의 규칙에 맞게, 삽입하려는 노드가 더 작으면 왼쪽 자식쪽으로 내려가고 더 크면 오른쪽 자식쪽으로 내려가서 null 이 되는 부분에 새로운 노드를 삽입한다. 어떻게 되든 기존 트리의 중간에 새로운 노드가 삽입되는 경우는 없다.
public void addNode(int key) {
if (findNode(key) != null) return; // 이미 존재하면 그냥 리턴
Node newNode = new Node(key);
if (root == null) {
root = newNode; // 트리가 비어있으면 root 에 삽입
} else {
Node focusNode = root; // 탐색용 노드
Node parent; // 탐색용 노드의 부모 노드
while(true) {
parent = focusNode; // 이동
if (key < parent.key) { // 삽입하려는 키가 현재 노드보다 작으면
focusNode = parent.leftChild; // 왼쪽으로 이동
if (focusNode == null) { // 왼쪽 노드가 비어있으면
parent.leftChild = newNode; // 왼쪽 노드에 삽입
return;
}
} else { // 삽입하려는 키가 현재 노드와 같거나 크다면
focusNode = parent.rightChild; // 오른쪽으로 이동
if (focusNode == null) { // 오른쪽 노드가 비어있으면
parent.rightChild = newNode;// 오른쪽 노드에 삽입
return;
}
}
}
}
}
탐색
특정 값을 가진 노드의 탐색도 삽입과 비슷한 과정을 거친다.
public Node findNode(int key) {
// 트리가 비었을 때
if (root == null) return null;
Node focusNode = root;
while (focusNode.key != key) {
if (key < focusNode.key) { // 현재노드보다 작으면
focusNode = focusNode.leftChild; // 왼쪽으로
} else { // 크면
focusNode = focusNode.rightChild; // 오른쪽으로
}
// 찾으려는 노드가 없을 때
if (focusNode == null)
return null;
}
return focusNode;
}
순회
위키 에 진짜 설명이 잘 돼있어서 굳이 따로 정리할 필요가 없을 것 같다.
요약해서 몇 가지만 기억해두자면
- 전위(preorder), 중위(inorder), 후위(postorder) 순회는 root 노드를 기준으로 전위는 root 를 먼저, 중위는 root 를 중간에, 후위는 root 를 마지막에 방문한다는 것이다.
- 전위순회는 Depth First Search (깊이 우선 탐색, DFS) 라고도 부른다.
- 전위순회인 DFS 는 전위표기법을 구하는데 사용할 수 있다.
- 레벨순서 순회는 Breadth First Search (너비 우선 탐색, BFS) 라고도 부른다.
코드는 단순하다.
public void inOrderTraverse(Node focusNode) {
if (focusNode != null) {
inOrderTraverse(focusNode.leftChild);
System.out.print(focusNode.key + " ");
inOrderTraverse(focusNode.rightChild);
}
}
public void preOrderTraverse(Node focusNode) {
if (focusNode != null) {
System.out.print(focusNode.key + " ");
preOrderTraverse(focusNode.leftChild);
preOrderTraverse(focusNode.rightChild);
}
}
public void postOrderTraverse(Node focusNode) {
if (focusNode != null) {
postOrderTraverse(focusNode.leftChild);
postOrderTraverse(focusNode.rightChild);
System.out.print(focusNode.key + " ");
}
}
삭제
삭제의 경우 조금 까다롭다. 어느 데이터 구조든 삭제 작업은 항상 다른 작업보다 까다로운 것 같다.
세 가지 경우를 생각해 볼 수 있다
- 삭제하려는 노드의 자식이 없는 경우
- 삭제하려는 노드의 자식이 하나만 있는 경우
- 삭제하려는 노드의 자식이 둘 다 있는 경우
각각의 경우에서 공통점을 살펴보면
- 세 가지 모든 경우에서 삭제하려는 노드의 부모노드를 기억하고 있어야 한다.
- 삭제하려는 노드가 부모노드를 기준으로 왼쪽 자식노드인지 오른쪽 자식노드인지 알아야 한다.
A 라는 노드가 삭제되면 A 의 부모노드와 A 의 자식노드를 연결시켜 주어야 이진탐색트리 구조가 깨지지 않는다.
- 1번의 경우, 삭제하려는 노드가 왼쪽 자식이라면 부모노드의 왼쪽 자식을 null 로 만들어주면 되고, 삭제하려는 노드가 오른쪽 자식이라면 부모노드의 오른쪽 자식을 null 로 만들어 주면 끝난다.
- 2번의 경우, 삭제하려는 노드가 왼쪽 자식이라면 부모노드의 왼쪽 자식을, 삭제하려는 노드의 왼쪽 자식과 연결시켜주면 되고, 삭제하려는 노드가 오른쪽 자식이라면 부모노드의 오른쪽 자식을, 삭제하려는 노드의 오른쪽 자식과 연결시켜주면 된다.
3번의 경우가 문제다
- 삭제하려는 노드의 오른쪽 sub tree 를 잠시 저장해둔다. (“대체노드”를 찾아서 오른쪽에 연결시킬 것이다)
- 삭제하려는 노드의 오른쪽 sub tree 에서 가장 작은 노드를 찾는다.
- 찾은 노드를 편의상 “대체노드” 라고 이름 붙이자.
- 삭제하려는 노드의 위치에 “대체노드”를 위치시킨다.
- 삭제하려는 노드가 왼쪽이었는지 오른쪽이었는지 기억해둔 것을 이용하여 부모노드의 왼쪽 혹은 오른쪽 자식으로 연결시킨다.
- 삭제하려는 노드의 부모노드가 가리키고 있던 왼쪽 sub tree 를 “대체노드”의 왼쪽 자식으로 연결시켜 준다.
- "대체노드"의 왼쪽 자식은 항상 null 이어야 한다.
- 삭제하려는 노드의 오른쪽 sub tree 에서 가장 작은 값을 찾은 것이기 때문이다.
- “대체노드”의 왼쪽 자식이 null 이 아니라면, 그 null 이 아닌 노드가 가장 작은 값인 것이니까 잘 못 찾은 것이다.
- 처음에 잠시 저장해 두었던 삭제하려는 노드의 오른쪽 sub tree 를 “대체노드”의 오른쪽 자식으로 연결시켜 준다.
- 이 과정에서 “대체노드” 와 오른쪽 sub tree 가 같다면, “대체노드”의 오른쪽 자식은 null 로 만들어 준다.
- “대체노드” 를 삭제하려는 노드의 위치에 위치시키면 원래 “대체노드”가 있던 위치는 null 이 되어야 하기 때문.
글만으로는 잘 이해되지 않을 것 같으니 그림을 그려보자… 아래 BST 에서 25 를 삭제하는 경우를 생각해보자.
삭제하려는 노드를 기준으로 오른쪽 sub tree 는 모드 삭제노드보다 큰 값, 왼쪽 sub tree 는 모두 삭제노드보다 작은 값을 가지고 있기 때문에, 삭제노드보다 큰 값을 가지는 오른쪽 sub tree 의 가장 작은 값이 삭제노드의 위치에 와야 이진탐색트리의 규칙을 지킬 수 있다.
삭제하려는 노드를 기준으로 왼쪽 sub tree 의 가장 큰 값을 대체노드로 사용해도 상관없다.
같은 BST 에서 15를 지운다고 생각해보면, 15의 오른쪽 sub tree 는 18이고 대체노드도 18이다. 이 경우 오른쪽 sub tree 를 null 해 주어야한다. 그렇지 않으면 18이 대체노드가 되고 18의 오른쪽 자식으로 또 18이 붙어있게 된다.
코드 대체노드를 찾는 메소드를 getRightMinNode() 라고 이름 붙였고, 이 메소드 안에서 대체노드의 부모의 left child 를 null 로 만들어 줌으로써 대체노드의 위치도 삭제시켜준다.
public boolean deleteNode(int key) {
// focusNode 와 parent 가 같을 수 있는 경우는 찾으려는 key 가 root 인 경우
Node focusNode = root;
Node parent = root;
boolean isLeftChild = true;
// while 문이 끝나고 나면 focusNode 는 삭제될 노드를 가리키고, parent 는 삭제될 노드의 부모노드를 가리키게 되고, 삭제될 노드가 부모노드의 left 인지 right 인지에 대한 정보를 가지게 된다
while(focusNode.key != key) {
parent = focusNode; // 삭제할 노드를 찾는 과정중(while문)에서 focusNode 는 계속해서 바뀌고 parent 노드는 여기서 기억해둔다
if(key < focusNode.key) {
isLeftChild = true; // 지우려는 노드가 왼쪽에 있는 노드냐 기록용
focusNode = parent.leftChild;
} else {
isLeftChild = false; // 지우려는 노드가 오른쪽에 있는 노드냐 기록용
focusNode = parent.rightChild;
}
// 찾으려는 노드가 없는 경우
if(focusNode == null) {
return false;
}
}
Node replacementNode;
// 지우려는 노드의 자식 노드가 없는 경우
if(focusNode.leftChild == null && focusNode.rightChild == null) {
if (focusNode == root)
root = null;
else if (isLeftChild)
parent.leftChild = null;
else
parent.rightChild = null;
}
// 지우려는 노드의 오른쪽 자식노드가 없는 경우 (왼쪽 자식 노드만 있는 경우)
else if(focusNode.rightChild == null) {
replacementNode = focusNode.leftChild;
if (focusNode == root)
root = replacementNode;
else if (isLeftChild)
parent.leftChild = replacementNode;
else
parent.rightChild = replacementNode;
}
// 지우려는 노드의 왼쪽 자식노드가 없는 경우 (오른쪽 자식 노드만 있는 경우)
else if (focusNode.leftChild == null) {
replacementNode = focusNode.rightChild;
if (focusNode == root)
root = replacementNode;
else if (isLeftChild)
parent.leftChild = replacementNode;
else
parent.rightChild = replacementNode;
}
// 지우려는 노드의 양쪽 자식노드가 모두 있는 경우
// 오른쪽 자식 노드의 sub tree 에서 가장 작은 노드를 찾아서 지우려는 노드가 있던 자리에 위치시킨다
else {
// 삭제될 노드의 오른쪽 sub tree 를 저장해둔다
Node rightSubTree = focusNode.rightChild;
// 삭제될 노드 자리에 오게 될 새로운 노드 (오른쪽 sub tree 에서 가장 작은 값을 가진 노드)
// 이 노드는 왼쪽 child 가 없어야 한다 (가장 작은 값이기 때문에)
replacementNode = getRightMinNode(focusNode.rightChild);
if (focusNode == root)
root = replacementNode;
else if (isLeftChild)
parent.leftChild = replacementNode;
else
parent.rightChild = replacementNode;
replacementNode.rightChild = rightSubTree;
// 지우려는 노드의 오른쪽 sub tree 에 노드가 하나밖에 없는 경우
if (replacementNode == rightSubTree)
replacementNode.rightChild = null;
replacementNode.leftChild = focusNode.leftChild; // 지우려는 노드의 왼쪽 sub tree 를 연결시킨다
}
return true;
}
private Node getRightMinNode(Node rightChildRoot) {
Node parent = rightChildRoot;
Node focusNode = rightChildRoot;
while (focusNode.leftChild != null) {
parent = focusNode;
focusNode = focusNode.leftChild;
}
parent.leftChild = null;
return focusNode;
}